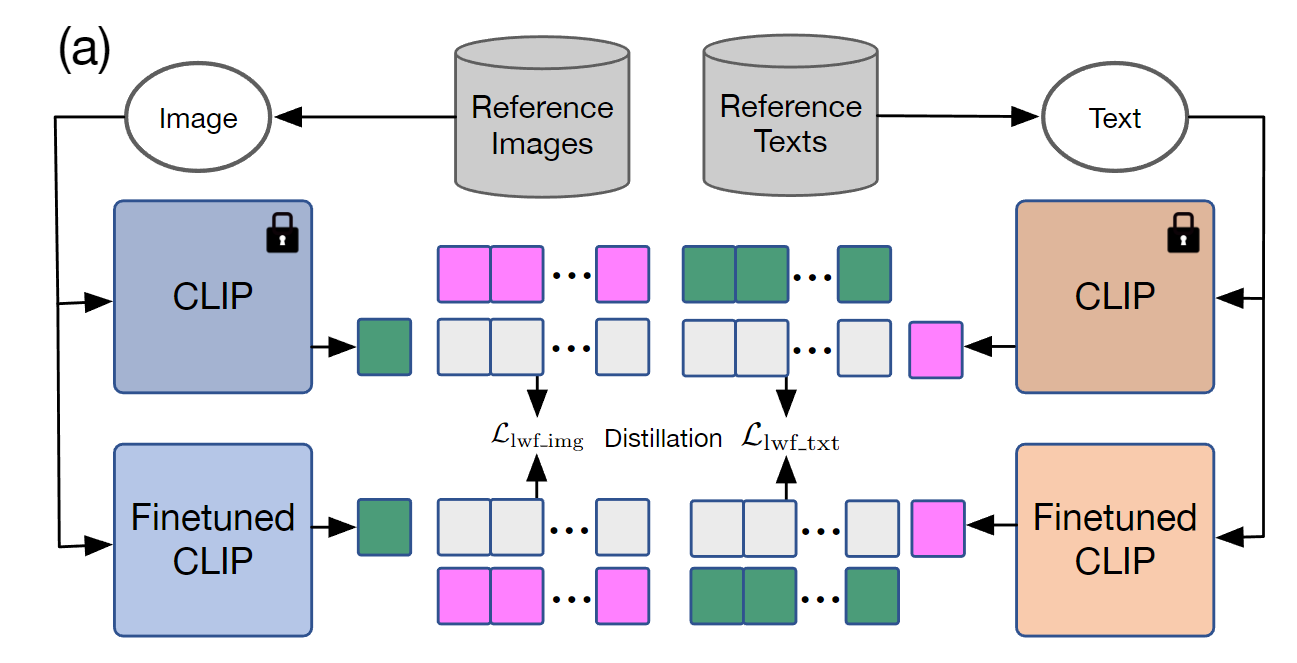
这篇文章使用了预训练的 CLIP 充当教师模型进行蒸馏,直接微调会导致模型的 zero-shot 能力变差,为了防止 feature 空间变化过大,训练损失不仅包括对当前任务的 fine-tune 损失(即交叉熵损失 Lce),还额外加入了从教师模型中蒸馏知识的两项正则化损失:Ldist_img 和 Ldist_txt。
L=Lce+λ⋅(Llwf_img+Llwf_txt)
其中
p=Softmax(s1,⋯,sm)
我们希望上述相似性分布能够在对所有潜在图像和文本进行微调的过程中保持稳定。给定一个教师模型 fˉ,可以应用蒸馏损失来惩罚与原始分布的偏离:
Ldist_img=CE(p,pˉ)=−j=1∑mpj⋅logpˉj
其中 pˉ 是由教师模型给出的分布。
为了缓解遗忘问题,一系列研究工作 [29, 74, 1] 在参数变化上施加了正则化损失。权重巩固引入了如下损失函数:
LWC=i∑(θi−θˉi)2,(5)
其中 θ 是当前模型的参数,θˉ 是参考模型的参数。尽管这种正则化方法可以防止遗忘,但在具有挑战性的持续学习(CL)设置下,它会阻碍对新任务的学习。
除了正则化损失之外,另一种在参数空间中的方法是集成不同模型的权重。Model Soup [68] 通过平均多个微调模型的权重来提升模型的鲁棒性,但会引入额外的训练成本。WiSE-FT [69] 提出在微调后的模型与原始模型之间进行加权平均,以提高对分布外预测的鲁棒性:
f(x;(1−α)⋅θ0+α⋅θ1),(6)
其中 θ0 是原始模型的参数,θ1 是微调后的模型参数。然而,该方法对超参数敏感,不同的 α 值会在零样本迁移能力和下游任务性能之间产生不同的权衡(如图 3 中的蓝色线所示)。
受此启发,我们将加权平均方法扩展到持续学习(CL)场景中。采用加权平均的动机是防止微调过程中丢失原始模型中的过多知识。随着训练的进行,模型在新任务上的表现越来越好,但在先前任务上的准确性逐渐下降。训练过程中的各个模型构成了一系列不同的“学习 - 遗忘”权衡。
与仅在初始模型和最终模型之间进行插值不同,我们的方法——权重集成(WE)在训练过程中对序列中的模型权重进行平均:
θ^t={θ0t+11θt+t+1t⋅θ^t−1t=0每 I 次迭代(7)
其中,模型权重采样每 I 次迭代发生一次。该方法与随机权重平均(Stochastic Weight Averaging, SWA)[26] 相关,但我们在此并未使用修改后的学习率调度策略,因为我们的目标不是提升泛化能力,而是改善学习与遗忘之间的权衡。如图 3 所示,WE 在下游任务上的表现优于 WiSE-FT。此外,尽管 WiSE-FT 对超参数 α 的取值较为敏感,而我们的方法在不同超参数(I)选择下具有更强的鲁棒性。
-7561599.D_DtiG-O_ONURN.webp)
