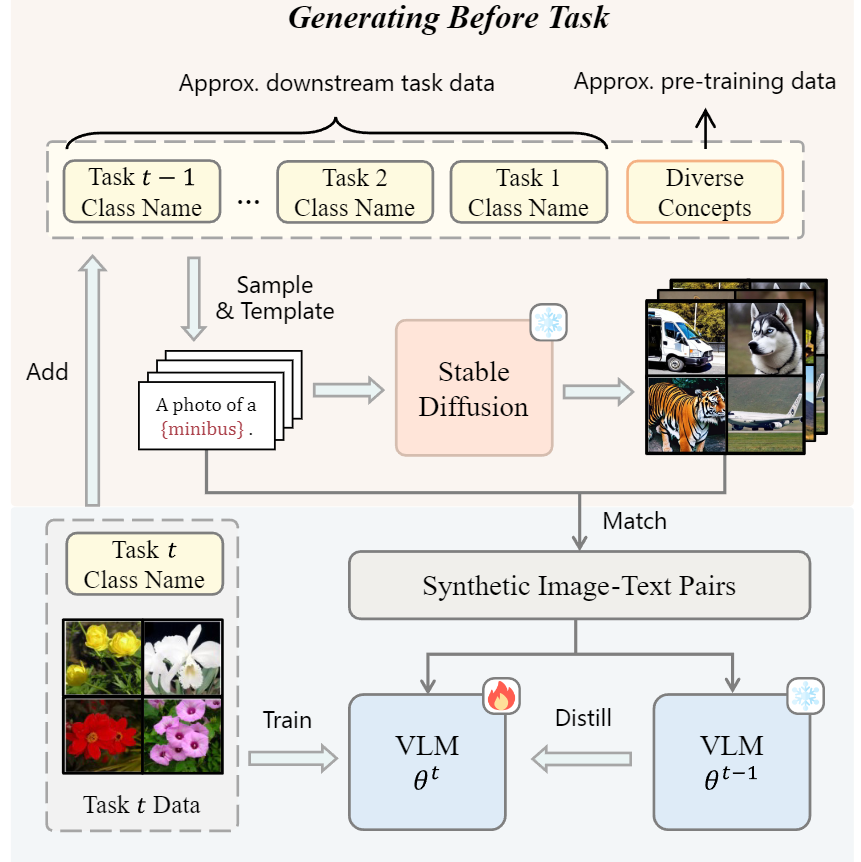
本文认为预训练的 Diffusion 模型和预训练的 CLIP 模型在训练数据的分部上类似,可以用生成模型来生成特定标签的数据,从而达到伪回放的效果。
对比损失#
在任务初始化的时候使用 ImageNet 的 class 作为一个标签池,后续任务的标签都加入标签池,然后在每个任务开始的时候生成一些数据来蒸馏。这里的蒸馏使用了上一个任务的模型和本次任务的模型之间的 KL 散度作为损失。
对于在任务 t 中包含 B 个图像 - 文本对的合成批次,当前模型 CLIP θt 将该批次编码为 l2 归一化的嵌入表示 {(z1t,w1t),(z2t,w2t),…,(zBt,wBt)}。随后计算批次内图像 - 文本的相似性,得到对比矩阵 Mt=[si,jt]B×B,其中 si,jt 表示余弦相似度 cos(zit,wjt)。类似地,我们使用上一个任务中的 CLIP 模型 θt−1 作为教师模型来计算 Mt−1。然后,利用 KL 散度 ,通过行对齐 Mt−1 和 Mt 来计算图像分类的知识蒸馏损失:
LKD_image=−B1i=1∑BMi,:t−1⋅log(Mi,:t−1Mi,:t),(2)其中 Mi,:t−1 和 Mi,:t 分别表示 Mt−1 和 Mt 的第 i 行。为了增强模态对齐,我们在列方向上对称地计算文本检索蒸馏损失:
LKD_text=−B1j=1∑BM:,jt−1⋅log(M:,jt−1M:,jt).(3)对视觉和文本模态均进行对称处理,整体对比蒸馏损失计算如下:
LCD=LKD_image+LKD_text.(4)然而教师模型也有遗忘,由于 Stable Diffusion 的预训练 ,生成的图像在 CLIP 的特征空间中与其对应的文本提示表现出强对齐性。我们利用这种对齐性作为硬目标来补充蒸馏软目标,纠正由教师模型错误引起的图像 - 文本不匹配,从而确保更可靠的知识保持。这里我们用单位矩阵 I 来表示硬目标,然后再和 Mt 得到 KL 散度 loss
LITA=LAlign_image+LAlign_text(5)结合用于学习新任务 t 的交叉熵损失 LCE,基于合成数据的蒸馏总训练损失 LTotal 可表示为:
LTotal=LCE+αLCD+βLITA,(6)其中,α 和 β 是超参数,用于平衡各项之间的权衡。
正则化#
我们引入自适应权重巩固作为正则化手段,以缓解过拟合问题,进而减少遗忘。为了实现更好的稳定性和可塑性平衡,我们在训练过程中利用合成图像 - 文本对的 Fisher 信息,自适应地调整对不同参数的约束程度。
在实践中,新任务的交叉熵通常占据主导,将模型分布推向一个和教师模型偏离的局部最优解,这种偏离会导致分布内过拟合以及蒸馏损失的增加,使得即使在蒸馏损失下降并收敛后,也难以回到教师模型所处的宽泛最优区域。EWC 就是一个典型的方法,但是其使用静态的 teacher 模型来约束,使得约束效果变差,因此,我们在整个过程中动态的计算 Fisher 信息矩阵。随着优化的进行,知识蒸馏损失成为模型遗忘程度的可靠指标。因此,我们直接将合成图像 - 文本对上的蒸馏损失作为对数似然,用于计算对角线 Fisher 信息:
Fθit(j)=∂θit∂(αLKD(j)+βLAlign(j))2,(8)其中,Fθit(j) 表示在第 j 次优化步骤中模型参数 θit 的对角 Fisher 信息。我们的自适应权重巩固损失随后定义为:
LAWC(j)=i∑Fθit(j)⋅(θit(j)−θit−1)2.(9)值得注意的是,Fθit(j) 也是蒸馏损失的梯度平方,反映了其稳定性。当学习的新任务与 CLIP 之前学习的任务存在显著差异时,LCE 的大部分梯度方向会与蒸馏损失的梯度方向相反。在这种情况下,LAWC 可以约束那些可能导致蒸馏损失剧烈变化的参数更新,即可能加剧过拟合和遗忘的参数更新。这有助于平滑多个优化目标之间的冲突,并稳定蒸馏损失,同时不牺牲模型的可塑性。我们对 Fisher 信息的自适应更新利用了蒸馏损失反向传播过程中的中间结果,引入的计算开销极小。
-7561599.D_DtiG-O_ONURN.webp)
