Methods#
对于基于 transformer 的 VQA 模型通常有 3 个 encoder,visual encoder/language encoder 和 fusion encoder。给定问题 q 和图像 v,公式可以表示为:
y^(v,q)=F(FT([VT(v);TT(q)])[0])其中,VT 和 TT 分别是预训练的视觉变换器编码器和文本变换器编码器,用于对图像 v 和问题 q 进行编码。FT(⋯)[0] 将多模态特征进行融合,并将第一个融合后的特征输入到分类器 F(⋅) 中以预测答案 a。
我们的目标是设计一些提示词和交互策略来解决 CL-VQA 问题。所以我们的公式被改为了:
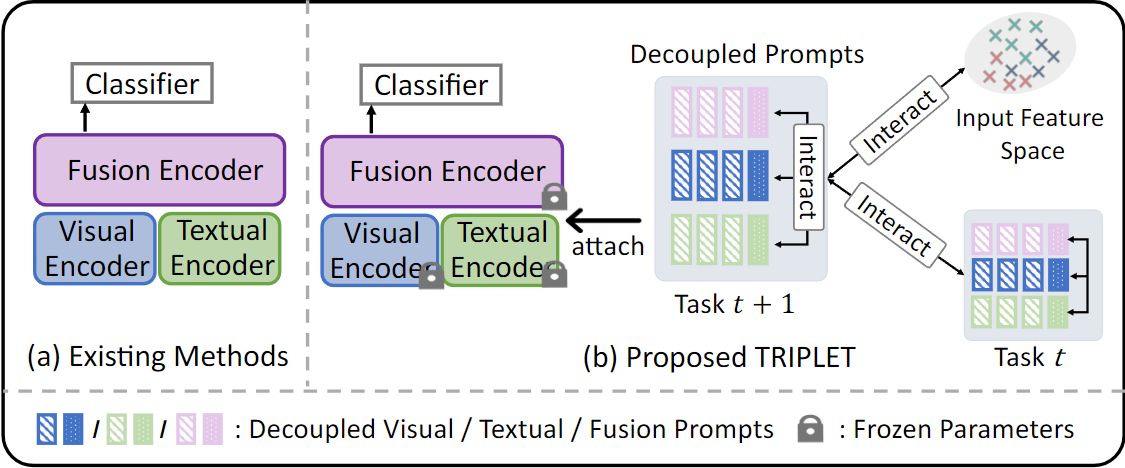
y^(v,q)=F(FT([P(f);VT([P(v);v]);TT([P(q),q])])[0]),(2)其中,P(v)、P(q) 和 P(f) 分别表示视觉提示、问题提示和融合提示。
选择性深度解耦
我们以逐层的形式对提示进行解耦,并将其附加到选定的层上。与将提示附加到所有选定的多头注意力(MHA)层 不同,本文采用一种替换式策略,仅在部分 MHA 层中添加提示,从而更加节省内存。给定一个包含 K 层的变换器 T,即 T([P;x])=(LK∘LK−1⋯∘L0)([P;x]),可以按层进行分解:
hˉkP=αk⋅hkP+(1−αk)⋅Pk,(3)[hk+1CLS;hk+1P;hk+1x]=Lk([hkCLS;hˉkP;hkx]),其中,[h0CLS;hˉ0P;h0x]=[CLS,P0,x] 是原始输入,而 LK 的输出被视为模型的最终输出。此外,αk∈{0,1} 是一个预定义的开关,用于控制是使用输出提示特征 hkP 还是第 k 层特定的提示 Pk 作为输入
互补解耦
遵循互补设计原则 ,每个提示被进一步划分为两部分:一个通用提示(G-Prompt),用于提取任务不变的知识;以及一个专家提示(E-Prompt),用于提取特定任务的知识。例如,视觉提示 P(v)={G(v);{E(v)}} 由所有任务共享的 G-Prompt G(v) 和专为第 t 个任务设计的 E-Prompt Et(v) 组成。当第 t 个任务到来时,我们训练提示 Pt(m)={G(m);Et(m)},其中 m=v,q,f。
在我们的实现中,我们将上述三种解耦设计相结合。也就是说,我们为三种模态分别设置了三组提示,每组提示包含逐层的深度提示,而每个逐层的深度提示又包含一个 G-Prompt 和一组 E-Prompts。总结来说,所有可学习的提示包括:
P(m)={Gk(m)∈RLG×D}⋃{Et,k(m)∈RLE×D},(4)其中,下标 t 表示任务,k 表示第 k 个多头注意力(MHA)层,LG/LE 分别表示 G-Prompt / E-Prompt 的长度,D 为嵌入维度。
提示词交互#
通过所提出的解耦提示,我们需要交互策略来将它们全部训练在一起。我们首先采用查询与匹配策略(Query-and-Match Strategy)来匹配输入特征与相关的任务特定提示。我们进一步引入模态交互策略(Modality-Interaction Strategy)和任务交互策略(Task-Interaction Strategy)来促进提示间的交互。前者会鼓励不同模态提示间的相互传播,从而增强模型性能。后者会使提示较少受到序列任务的影响,从而减少灾难性遗忘。
查询与匹配策略
由于我们解耦的提示中包含任务特定的提示,因此需要准确的任务特定键来将输入特征与这些提示关联起来。我们将文献中的“查询与匹配”(Query-and-Match)策略扩展到多模态领域,通过一个查询匹配损失 Lqm 来训练对应的任务特定键 ut(m),使得 ut(m) 更接近来自任务 t 的样本,而远离其他任务的样本。首先,给定 (v,q),查询通过冻结的变换器(见公式 (1))获得:
h(v)=VT(v),h(q)=TT(q),h(f)=FT([h(v),h(q)]),q(v)=h(v)[0],q(q)=h(q)[0],q(f)=h(f)[0],其中 h[0] 表示从向量中选择第一个元素,即选择 hCLS,如公式 (3) 所示。使用余弦相似度 γ,查询匹配损失 Lqm 定义为:
Lqm(Dt)=−(v,q)∈Dt∑m∈{v,q,f}∑γ(ut(m),q(m)).(5)这里也就是为每一个任务计算一个特征
模态交互策略
我们提出一种提示模态交互机制,作为不同模态提示之间的桥梁。我们引入如下交互映射:
P^t,k(f)=Wt,k(v)⊗Pk,t(v)+Wt,k(q)⊗Pt,k(q)+Wt,k(v,q)⊗(Pt,k(v)⊙Pt,k(q)),(6)其中 ⊙ 表示逐元素乘法,⊗ 表示矩阵乘法,W(⋅) 是可学习的交互矩阵。在本文中,我们对这些交互矩阵的秩进行约束,令 W=U⊗V⊤,其中 U,V∈RD×d 是两个低秩矩阵。我们使用以下 Lmod 来处理这种模态交互:
Lmod(Dt)=−k∑γ(P^t,k(f),Pt,k(f)).(7)这个损失函数鼓励生成的融合提示 P^t,k(f) 与原始的融合提示 Pt,k(f) 保持一致性,确保交互是有意义的。
任务交互策略
由于我们的基于提示学习的方法建立在冻结的预训练模型之上,不同任务的表示共享相同的语义空间。因此,提示在不同任务之间共享不变的语义空间,以与预训练模型对齐,这导致了不同任务之间具有不变的提示模态交互结构。为此,我们引入任务交互约束 Ltask 来调节这种不变结构,具体如下:
Ltask(Dt)=m,t,k∑(Wt,k(m)−⟨Wt,k(m)⟩t−1F2),(8)其中,∥⋅∥F 表示 Frobenius 范数,而 ⟨Wk(m)⟩t−1 是在训练第 (t−1) 个任务时缓存的 Wk(m) 的副本。通过约束 W 的变化幅度,防止新任务的学习过度改变已学习的模态交互模式,从而减少灾难性遗忘。
4.2.3 训练与推理#
训练
当一个新任务 t 到来时,我们将 F 实例化为一个分类器 gt(一个全连接层),并分配任务特定的查询键 (ut(v),ut(q),ut(f)) 和提示 (Et(v),Et(q),Et(f))。然后,解耦提示、交互矩阵、分类器和查询键通过以下联合损失函数进行共同训练:
L(Dt)=(v,q,y)∈Dt∑ℓCE(y^(v,q),y)+λ1Lqm(Dt)+λ2Lmod(Dt)+λ3Ltask(Dt),(9)其中 y^(v,q) 是网络的预测结果(见公式 (2)),y 是目标答案,ℓCE(y^,y) 是交叉熵损失,λ(⋅) 是超参数。
推理
在推理阶段,给定一个输入样本 (v,q),我们选择最佳匹配的任务索引 argmaxtγ(ut(m),Q(m))。然后选择对应的提示 Pt(m)(m),并将其输入到相应的变换器中。最后,选择对应的分类器 gt(⋅) 来预测答案。
-7561599.D_DtiG-O_ONURN.webp)