-7561599.D_DtiG-O_ONURN.webp)

73 字
1 分钟
Visual Instruction Tuning
Visual Instruction Tuning
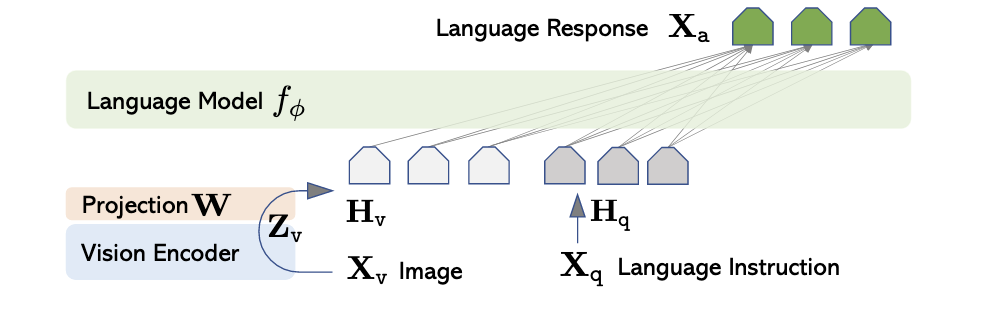
主要是使用 CLIP 的 ViT 来当 visual encoder,然后使用一个投影层吧 ViT 的输出映射到 LLM 的 embedding 空间中。
其中训练氛围两步
- 冻结 ViT 和 LLM,只训练投影层,用来对其特征空间
- 训练投影层和 LLM
Visual Instruction Tuning
https://f1yingwhite.github.io/posts/machinelearning/nlp/llm/mllm/liuvisualinstructiontuning2023/