https://www.zhihu.com/question/41765860
我们常用的贝叶斯公式求后验分布 P(Z∣X) 的时候常用
P(Z∣X)=∫zp(X,Z=z)dzp(X,Z)
但是这里使用贝叶斯求解是很困难的,因为我们的积分 z 通常是一个高维随机变量。在贝叶斯统计中,所有对于未知量推断的问题可以看作是对后验概率的计算,因此提出了变分推断来计算后验概率。
他的思想主要包括:
- 假设一个分布 q(z;λ)
- 通过改变分布的参数 λ 来使得我们假设的分布尽可能靠近 p(z∣x)
一言以蔽之,就是为真实的后验分布引入了一个参数化的模型,也就是用简单的分布来拟合复杂的分布,这种计算测率将计算 p(x∣z) 转化为了优化问题:
λ∗=argλmindivergence(p(z∣x),q(z;λ))
这里就是求 kl 散度最小
首先是一个公式的等价转换
logP(x)=logP(x,z)−logP(z∣x)=logQ(z;λ)P(x,z)−logQ(z;λ)P(z∣x)两边同时对 Q(z) 求期望得到
Eq(z;λ)logP(x)logP(x)logP(x)=Eq(z;λ)logP(x,z)−Eq(z;λ)logP(z∣x)=Eq(z;λ)logq(z;λ)p(x,z)−Eq(z;λ)logq(z;λ)p(z∣x)=KL(q(z;λ)∥p(z∣x))+Eq(z;λ)logq(z;λ)p(x,z)=KL(q(z;λ)∥p(z∣x))+Eq(z;λ)logq(z;λ)p(x,z)TIPhttps://blog.csdn.net/mch2869253130/article/details/108998463
kl 散度的公式为:DKL(p∥q)=∑i=1Np(xi)log(q(xi)p(xi)),是使用后面的分布近似前面的,而反向 kl 散度是用前面的近似后面的.
两者的区别在于:对于正向 kl 散度,想要最小化 kl 散度,在 px 大的地方需要 qx 也大而在 px 小的地方 qx 没有太多影响,所以得到的是一个较宽的分布。而对于反向 kl 散度,在 px 大的地方可以忽略,而在 px=0 的地方 qx 也要趋向于 0,也就是得到一个较窄的分布。
例子:假设现在有一个两个高斯分布混合的 px,qx 是单个高斯,用 qx 来近似 px,下面两种 kl 散度如何选择?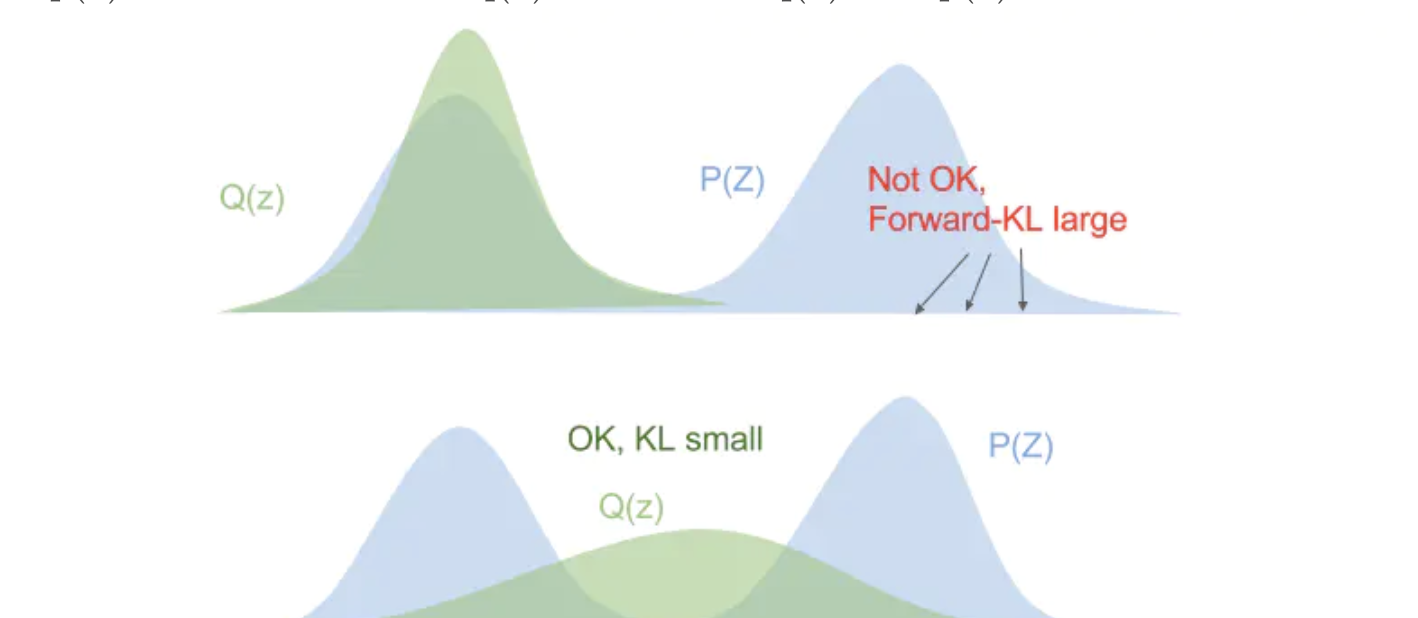 对于正向来说,他选择第二个,它更在意常见事件,当 p 有多个峰的时候,q 选择把这些峰模糊在一起。而对于反向 kl 散度来说,qx 的分布更符合第二行,反向 kl 散度更在意 px 中的罕见事件,保证符合低谷的事件。
对于正向来说,他选择第二个,它更在意常见事件,当 p 有多个峰的时候,q 选择把这些峰模糊在一起。而对于反向 kl 散度来说,qx 的分布更符合第二行,反向 kl 散度更在意 px 中的罕见事件,保证符合低谷的事件。
回到我们前面的问题,我们的目标就是最小化 q 对 p 的 kl 散度,为了最小化 kl 散度,也就是求解 (这里使用了反向 kl 散度)
λmaxEq(z;λ)logq(z;λ)p(x,z)=ELBO这里的 p(x) 一般被称为 evidence,又因为 kl 散度大于 0,所以 logp(x)≥Eq(z;λ)[loglogq(z;λ)p(x,z)]
所以最后的公式为:
log(P(x))=KL(q(z;λ)∣∣p(z∣x)+ELBOEM 算法就是利用了这一特征,但是 EM 算法假设了 p(z|x) 是易于计算的形式,变分则无这一限制。
黑盒变分推断(BBVI)#
对于 ELBO 公式,使用参数 θ 代替 λ,并对其求导
∇θELBO(θ)=∇θEq(logp(x,z)−logqθ(z))展开计算的到
∂θ∂∫qθ(z)(logp(x,z)−logqθ(z))dz=∫∂θ∂[qθ(z)(logp(x,z)−logqθ(z))]dz=∫∂θ∂(qθ(z)logp(x,z))−∂θ∂(qθ(z)logqθ(z))dz=∫∂θ∂qθ(z)logp(x,z)−∂θ∂qθ(z)logqθ(z)−∂θ∂qθ(z)dz因为
∫∂θ∂qθ(z)dz=∂θ∂∫qθ(z)dz=∂θ∂1=0所以
∇θELBO(θ)=∫∂θ∂qθ(z)(logp(x,z)−logqθ(z))dz=∫qθ(z)∂θ∂logqθ(z)(logp(x,z)−logqθ(z))dz=∫qθ(z)∇θlogqθ(z)(logp(x,z)−logqθ(z))dz=Eq[∇θlogqθ(z)(logp(x,z)−logqθ(z))] 