
Abstract
本篇论文映入了一个新的任务叫做跨模态泛化(CMG),他反应了从成对的多模态数据中学习统一离散表示的挑战.在后续的下游任务中,模型可以在只有一模态被标记的任务对其他模态中取得不错的零样本泛化能力.现有的多模态表示学习方法更多的关注粗粒度的对齐或者依靠信息在不同模态中是完全对齐的假设,这种假设在真实世界中并不实际.为了解决这个限制,我们提出了Uni-Code,能够包含两个关键贡献:双重夸模态信息解耦和多模态指数移动平均.这两个贡献促进了多模态的双向监督.并且在共享的离散潜在空间中进行等价语义信息的对齐.从而实现多模态序列的细粒度统一表示.
Introduction
近年来的多模态领域取得了巨大的进展,但是标注这些任务会花费巨大的人力.此外给不同的模态进行数据标注花费的人力也不同,导致通常只有一种模态被标记了.比如,基于文本的分割很多但是基于语音的分割很少,在这些有限的数据集上进行训练会阻碍他们的应用场景.幸好今年来出现了很多不需要标注的多模态训练.因此,在本文中我们提出了一种新的任务,CMG(跨模态泛化)来探索如何从未标记的多模态数据对中学习一个统一的离散表示.我们的目标是从标记数据中的知识迁移到其他的未标记任务中来增加泛化性.
人类有天然的能力来联系相同语义的多个模态,根据已知的知识来迁移到别的模态上.基于此,许多的研究探索了把多模态的数据聚合到一个统一的语义空间中,其中这些方法可以被分为两类:隐式表示和显示表示.隐式表示使用模态无关的编码器来表现不同的模态,或者使用对比学习把不同的模态数据高纬空间中拉进.相比之下,显示表示只在使用一个统一的 codebook 或者 prototype 来表示不同的模态来促进跨模态的稳定对齐.此外,使用离散空间可以让相似的输入特征在高维空间聚合,使用更少的 code 来表示复杂的特征.但是这些方法只是在量化之前把特征序列压缩为单个向量,或者依赖多模态是完全对其的假设.因此这些方法只适用于简单任务.
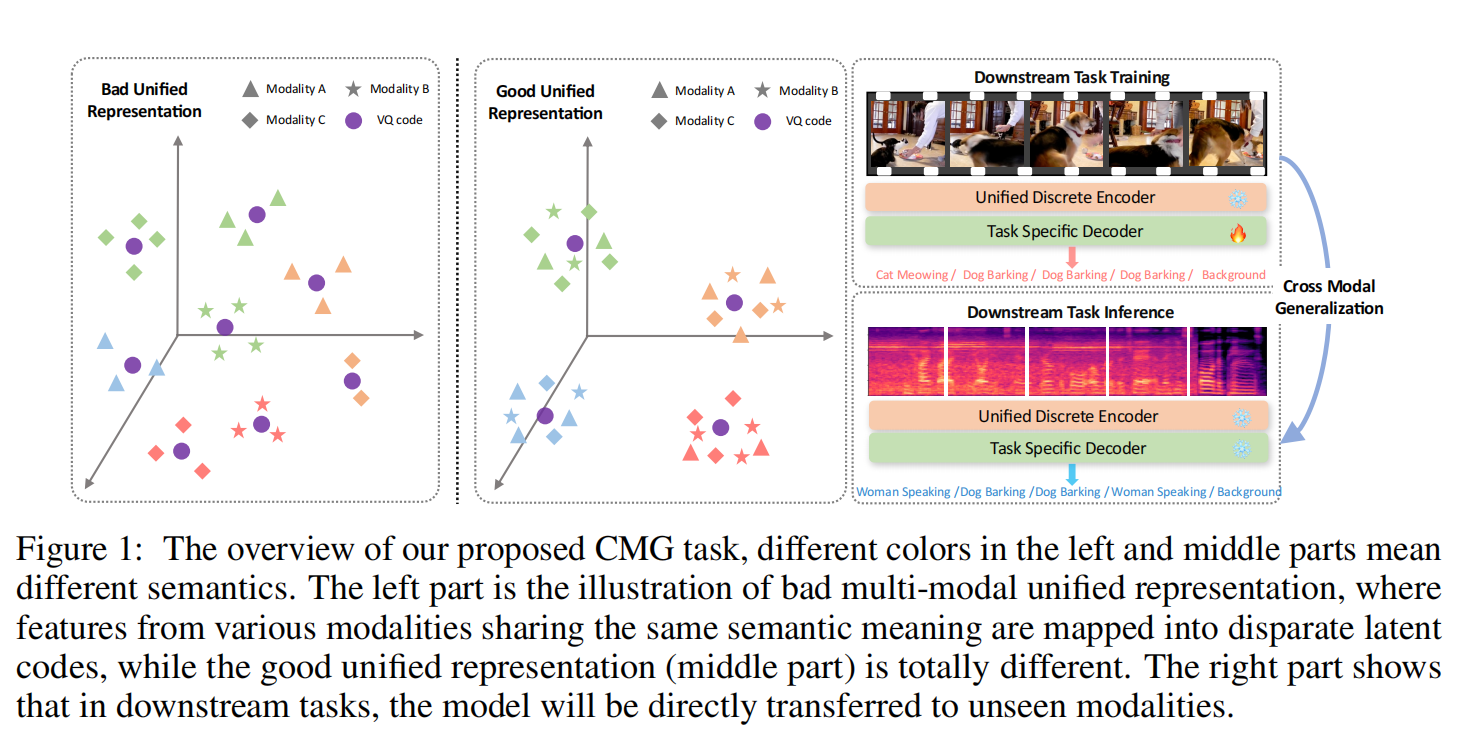 如图 1 所示,在无限制的视屏中包含猫和狗叫,但是音频信息包含女人说话和狗叫,直接使用先前的方法会导致多模态信息的不准确映射.为了解决这种限制,我们的论文主要关注如何得到一种细粒度的多模态序列的统一表示.我们解决这个问题有两个主要的方法:1. 从不同的模态中提取相同的语义信息同时减轻模态特定的语义信息的细节影响. 2. 使用相同的代码来表示不同模态中具有相同语义信息的多模态. 之前的工作主要关注第二点,而忽略了低一点
如图 1 所示,在无限制的视屏中包含猫和狗叫,但是音频信息包含女人说话和狗叫,直接使用先前的方法会导致多模态信息的不准确映射.为了解决这种限制,我们的论文主要关注如何得到一种细粒度的多模态序列的统一表示.我们解决这个问题有两个主要的方法:1. 从不同的模态中提取相同的语义信息同时减轻模态特定的语义信息的细节影响. 2. 使用相同的代码来表示不同模态中具有相同语义信息的多模态. 之前的工作主要关注第二点,而忽略了低一点
对于第一个方面,我们提出了双重夸模态信息解耦模块,能够保留主要信息的同时区分模态特点信息(比如光线,音色等模态特定内容).然而,缺乏有效的指导使得模型难以识别哪些语义信息是有用的。受多模态信息互补性指导的启发,我们提出了一种新颖的 Cross-CPC 方法,基于当前模态的已知序列信息预测其他模态的未来信息,从而有效地最大化不同模态之间的细粒度互信息。对于第二个方面,我们使用多模态指数移动平均模块将不同模态编码具有共享语义的量化向量聚合到相同的潜在编码空间中
Cross Modal Generalization Task
给定一个多模态成对的数据 of size N,ABC 表示不同的模态.跨模态泛化的任务旨在在预训练阶段把不同的模态映射到一个统一的离散空间中,让具有相同语义的离散潜在编码能够在不同模态之间共享.而后在下游任务中,当只有一种模态有标注信息的时候,样本可以基于预训练信息获得的共享离散空间,把从 A 学习到的知识迁移到别的模态从而实现零样本泛化能力.
Unified Representation Learning
与先前简单的从成对数据中提取信息然后直接映射的方法不同,我们认为统一表示的成果在于模态无关特征的提取.因此在这片文章中,我们映入了 DCIA 在提取细粒度的语义信息然后将其与每个模态的特定信息分离,第二,我们将信息使用 VQ-VAE 进行压缩,保证通过重构损失后重构的离散变量仍然能够保持原始的语义信息.为了简化,我们使用两个模态来展示这个过程.图 2 展示了我们的任务的流程
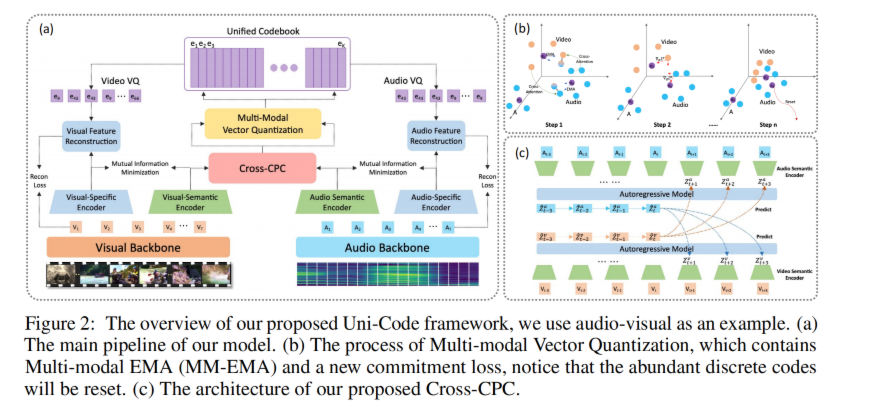
Baseline
对于给定的两个模态,我们首先使用语义编码器来提取模态无关信息 za 和 zb,并且使用两个模态特定的 encoder来提取剩下的信息得到.TD 分别表示时间和维度.不同模态的 za 和 zb 的维度不一样.我们使用 vector quantized 操作来把语义特征 za 和 zb 投影到细粒度的潜在空间中. , where ,也就是和她最近的离散变量. 潜在空间的 codebook 在两个模态之间共享,其中 L 是离散潜在空间的大小,最终我们把合起来重构原始特征
其中 sg 是停止梯度.重构损失函数能够保证压缩的潜在空间编码 el 保持不同模态的语义特征,在理想情况下,来自不同模态的 za 和 zb 具有相同语义能够被映射到同样的离散潜在空间.但是没有高效的监督,模态之间存在的差异会导致 za 和 zb 陷入不同的区域 of codebook.
Dual Cross-modal Information Disentangling
我们从两个方面介绍了我们的 DCID 模块:一是通过条件互信息下界(CLUB)在每个模态中最小化模态无关语义特征与模态特定特征之间的互信息,二是通过跨模态对比预测编码(Cross-CPC)在不同模态之间最大化模态无关语义特征的互信息。 基于 CLUB 的互信息最小:相较于尝试优化互信息下界的方法,我们的方法能够高效的优化互信息上界,在信息分离方面有着天然的优势.给定两个变量 x 和 y,目标函数定义如下:
…一些公式 。然而,仅使用 CLUB 来最小化互信息,模型在识别相关语义特征时仍面临挑战。由于配对的多模态信息可以相互提供指导,并作为彼此的监督信号,我们提出 Cross-CPC 方法来缓解此问题。 使用Cross-CPC的互信息最大…一些公式
Multi-modal Exponential Moving Average
…