
[!PDF|yellow] Page.2
a universal pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing of both static images and dynamic videos.
能够干基本所有的视觉任务的神秘架构
Vitron 在前端采用了集合了 image,video,像素级别的视觉 encoder.在后端集成了最专业的视觉专家,让 Vitron 覆盖了基本所有的视觉任务。为了确保从 LLM 到后端模块进行功能调用时有效且精确的信息传递,通过同时整合离散的文本指令和连续的信号嵌入我们提出了一种新颖的混合方法。此外,我们设计了多种像素级时空视觉语言对齐学习,以使 VITRON 达到最佳的细粒度视觉能力。最后,建议一个跨任务协同模块,以学习最大化任务不变的细粒度视觉特征,增强不同视觉任务之间的协同。
Introduction
今年来的 MLLM 发展迅速,大量有价值的研究被提出.通过使用纯语义的模型来扩展到 MLLM,在多种任务上体现了鲁棒性.后续的研究旨在扩展 MLLM 的能力,分为为两个方向,
- MLLM 对视觉的理解不断加深,从粗略的实例级转为像素级,从而实现视觉定位的能力.
- 另一方面,尝试对 MLLM 的功能进行扩展,不仅能够理解输入的视觉信号,还能支持视觉内容的生成和输出 我们认为 MLLM 的能力未来应该包含更高维度的统一,也就是多模态专家.但是我们发现目前的发展仍然没有达到高度的统一.
- 目前的模型要么只支持视频要么只支持图片
- 目前模型的功能不足,要么只理解,要么只生成 我们希望未来的模型啥都能干,达到 OFA 的幻想.对于一个能通才来说,重要的是如何在多个任务上都尽可能达到 SOTA,这包括
- 来自 LLM 的指令精确的产地给了下游任务.
- 不同的任务相互合作
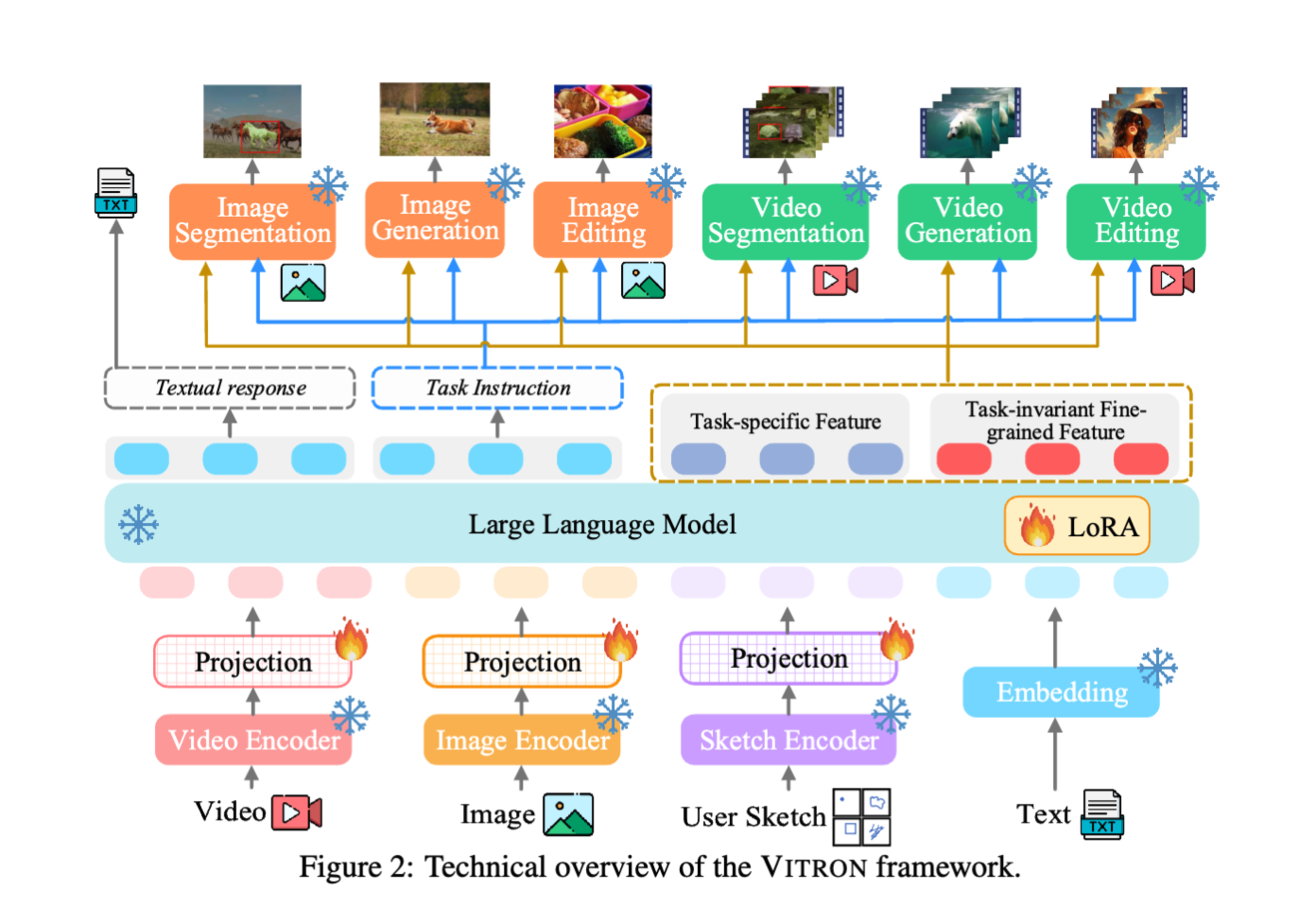
首先,VITRON 利用主干 LLM 进行理解、推理、决策和多轮用户交互。为了感知细粒度的 image 和 video 信息,vitron 整合了 image,video 和区域框指定的输入编码器.另一方面,几个 SOTA 的 image 和 video 模块被集成用来进行 decode 和执行广泛的视觉任务.
为了保证模型的指令被准确的送到多个后端执行对应的任务,我们设计了一种新的指令传递混合方法.特定来说,LLM 不仅输出离散的文本型号,还输出了连续的信号特征 embedding,最后,为了最大化子模块的效果,我们还是用了一个协同模块,其中我们充分最大化了任务持久的细粒度视觉特征,以便在不同的视觉任务之间共享。
训练方法如下:
- front encoder 和 LLM 的 vision 和 Language 对齐
- 面相调用的指令微调
- LLM 和 backend 的面相嵌入的对齐调优
此外,我们还进一步增强了能力一方面,我们引入了细粒度时空视觉定位指令调优,训练 LLM 以进行定位预测和对图像及视频的像素感知,使得 VITRON 能够充分获得像素级的视觉感知。另一方面,我们利用对抗训练将信号特征表示中的任务特定特征与任务不变的细粒度视觉特征解耦,从而增强不同任务之间的协同作用
[!PDF|red] Page.4
et these models might lack an LLM as a central decision processor, unable to flexibly interpret user intent or execute tasks interactively
目前的模型很牛,但是缺少一个 LLM 来进行中央决策,不能灵活的执行用户的命令.
[!PDF|yellow] Page.4
fall short in supporting pixel-level in-depth vision understanding and comprehensive support for vision operation tasks.
缺少相似级别的视觉理解
[!PDF|red] Page.5
et simply integrating existing visual specialists into an LLM to form MLLMs is not sufficient enough, as genuine human-level AI should possess universal intelligence with robust cross-task generalizability
只是搭积木是不够的,因为真正的人类级别的 AI 应该具有具有强大的跨任务泛化能力的通用智能因此需要考虑如何在模型内部让这些模块相互合作
对于大模型的生成能力,关键在于有效且公正的吧多模态大模型的语义理解能力传送给主干编码器,一种是离散的文本指令,另一种是连续的嵌入信号,我们发现这两种方法是互补的,前者让 llm 能够高效的通过简单的文本来传递任务指令目标,后者能够带来任务所需要的特征,在这个任务中,我们把这两者结合在了一起.
Architecture of Vitron
VITRON 是经典的 encoder-llm-decoder 架构,
基础的理解和生成能力训练
总体的 VL 对齐学习: 为了保证视觉与语言被映射到同一个特征空间,跟随前人的脚步,我们使用 image-caption 进行训练,让 LLM 来生成描述或者 caption(训练 projection 层) 调用导向的指令微调: 在上一个训练阶段,使大语言模型(LLM)和前端编码器具备了理解视觉的能力。而这一阶段,调用导向的指令微调,旨在赋予系统准确执行命令的能力,使 LLM 能够生成合适且正确的调用文本,这一部分的输出包括
- LLM 的文本输出
- 调用模块名称
- 调用命令: 比如 segmentation
用来分割 clock - regin: 表示框选区域 我们必须自己创建微调指令集,通过和 GPT-4 的通力协作,我们最终实现了这个数据集
嵌入导向的解码器对齐: 除了生成指令来选择下游模块,LLM 还需要把特征信号传输给模块,我们把 LLM 生成的特征分为任务有关和任务无关特征. 根据 NExTGPT,我们通过解码器的投影层将特征嵌入与所有的视觉模块的输入编码器对齐.通过最小化投影后的特征和模态输入 encoder 之间的距离进行对齐.
细粒度时空视觉定位指令微调
核心思想是使大语言模型(LLM)能够定位图像的细粒度空间信息和视频的详细时间信息。
图片空间定位: 让大模型输出 bounding box
视频空间定位:
具备定位意识的视觉问答:: 上述的定位任务仅涉及视觉感知的低级层面。然而,在许多场景中,LLM 需要具备基于低级像素定位的高层次、深入的视觉推理能力。因此,我们进一步引入了具备定位意识的视觉问答任务,包括 Image-QA 和 Video-QA ,使 LLM 能够基于定位结果执行语义层面的问答任务。
跨任务协同学习
直接使用多个专家的问题就是: 如何确保不同的模块协同工作?否则他们结合在一起是无意义的.为了实现这个,我们把信号特征嵌入转换为任务无关特征和任务有关特征,直觉上,由于我们关注的任务是细粒度的,因此任务不变的细粒度特征在模态之间共享的越多,任务的互相收益就越大.因此我们引入了跨任务协同学习模块,采用对抗训练来讲任务特定与无关特征进行解耦.首先允许一个主干视觉专家通过这两种特征 (concat 在一起的) 进行预测,同时让一个第三方判别器根据共享的特征来判断当前的任务是那个任务.理想情况下,如果判别器无法识别任务,则共享的特征就可以被认为训练成功了.