
[!PDF|yellow] Page.1
However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs.
现有的使用编码器会带来强烈的归纳偏置,比如分辨率,纵横比和语义先验,影响了 LLM1de 效率
Introduction
通常,视觉编码器专注于提取高度压缩的视觉表示,然后和语言模型进行适应 来处理视觉语言对其和指令微调,不管怎么样,这样的脚骨有如下几点问题:
-
输入图片的大小固定
-
模型越来越大,用于部署的开销也越来越大
-
LVM 和 LLM 之间的模型能力不一定对等 因此我们思考: 是否可能吧 VE 和 LLM 集成到一个单一的统一架构中?从零开始构建无编码器 VLMs 的根本问题在于:
-
由于缺少高质量的 image-text 数据,直接训练一个 encoder-free 的 LLM 是很消耗资源的,难以学习夸模态的知识和通用表示.因此,我们将 LLMs 定位为核心枢纽,并努力促使 LLMs 本身在保持原有语言能力的同时发展视觉感知能力.
-
视觉识别能力: 传统的对比学习和自回归生成本质上促使视觉骨干网络生成高度压缩的整体语义而忽略细粒度的特征. 我们在 2 个 8 卡 40G 的节点上训练了 9 天,发布了 EVE7B
Related Work
Encoder-based VLM
随着 LLM 的发展和大视觉模型的发展,在 LLM 中集成 LVM 成为了发展 VLM 的主流方法,最近的一些研究也发现了输入图像大小和宽高比的重要性,特别是在文档,表格这类文件中.但是,首先的预训练像素大小限制了将高分辨率图片进行切片再输入,或者使用低分和高分双路编码器架构,导致图像失真.
[!PDF|yellow] Page.3
Some studies [ 40 , 42 ] highlight the notable benefits via substituting CLIP-ViT-B with stronger CLIP-ViT-L-336px in enhancing multimodal models alongside Vicuna-7B [ 11 ]. Conversely, other findings [ 55 ] indicate that larger vision encoders may not be necessary, as features of multi-scale smaller ones can approximate their performance. Moreover, recent state-of-the-art approaches [10 , 60 ] exhibit significant performance improvements by introducing extremely LVMs. B
如何在 VLM 平衡 LLM 和 LVM 的能力目前仍然是一个充满争议的问题
Encoder-Free VLM
Fuyu-8B 是一个完全的 decoder only 的网络,不依赖视觉编码器,它能够处理任意大小的图像,因为 patch 通过投影层直接输入 LLM 中.(1)在扩大预训练数据规模之前,优先从以 LLM 为中心的视角进行视觉 - 语言预对齐至关重要。这一步基础性操作稳定了训练过程,并缓解了整合视觉和语言信息时的优化干扰。(2)通过视觉表示监督和语言概念对齐来增强图像识别能力,为各种视觉 - 语言任务生成更强的视觉表示。
Methodology
首先我们部署了 Vicuna-7B 来获得丰富的语言知识和强大的指令微调能力.在无编码器前提下,我们构建了一个轻量的 patch embedding 层来编码图像并且把文本高效的输入到网络中.在获得了网络的输出后,我们尝试通过分层 patch 对齐层,把 patch 特征和来自视觉编码器的特征进行对齐,通过交叉熵损失由多源基于编码器的 VLMs 生成下一个词标签.
Patch Embedding Layer
我们使用简洁并且可训练的模块来近乎无损的传递图像而不是使用深度 encoder 来压缩图像变成高维空间表示.
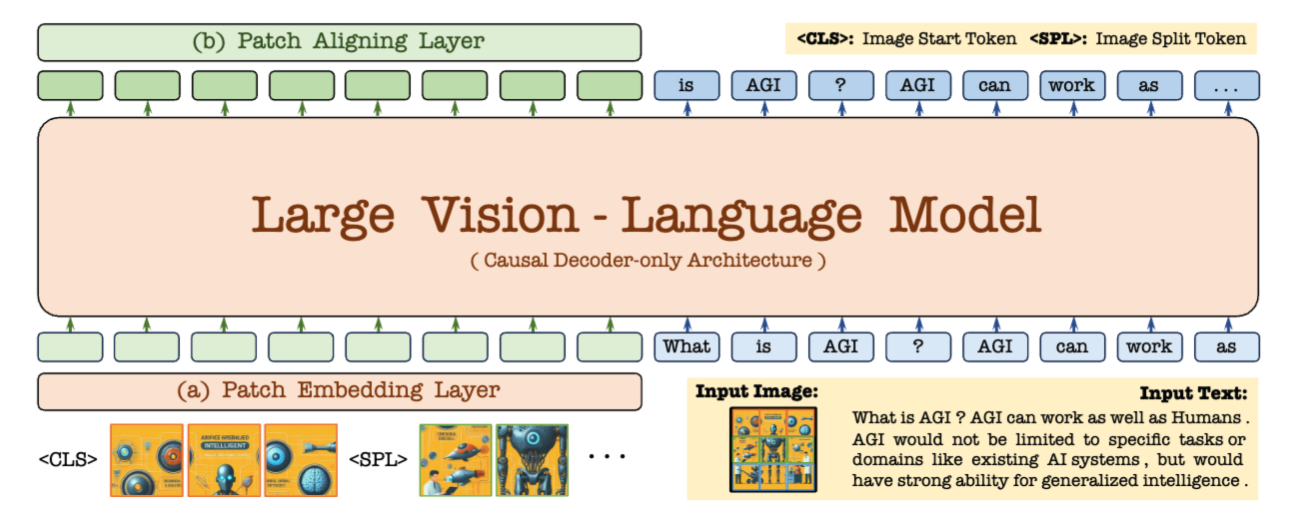
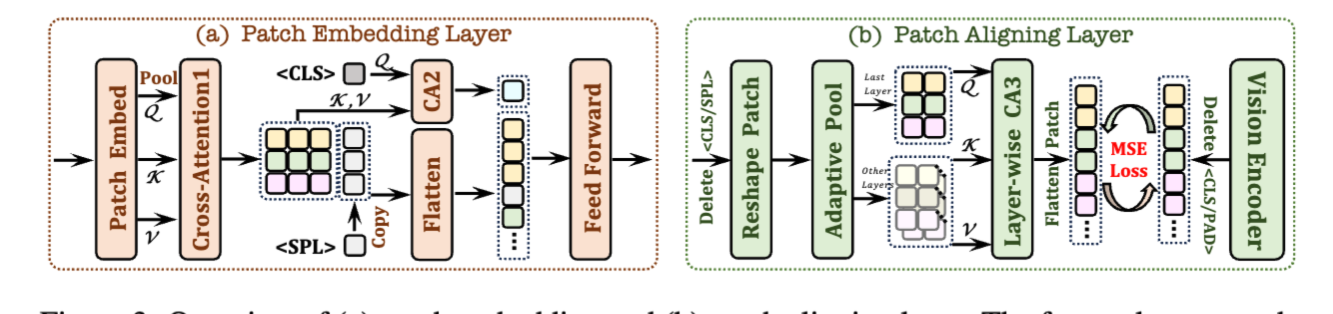
Patch Embedding Layer: 给定一个 (H,W) 的图像,我们首先使用卷积层获得大小为 (h,w) 的 2D 特征图,为了灵活的控制计算开销,我们在每个未交叉的特征切片中使用一个平均池化。为了进一步增强这些下采样的特征,在每个结果特征与其对应的切片之间应用了一个具有有限感受野的交叉注意力(CA1)层。此外,我们还在一个特殊的<CLS>标记与所有 Patch 特征之间引入了另一个交叉注意力(CA2)层。所获得的特征作为图像的起始符号,为后续骨干网络中的 Patch 特征提供整体信息。考虑到图像输入的不同纵横比,我们在每行 Patch 特征的末尾插入一个可学习的换行<SPL>标记,以帮助网络理解图像的二维空间结构和依赖关系。最后,我们将这些特征展平并通过一个两层前馈层,然后与文本嵌入一起连接成一个统一的仅解码架构。需要注意的是,输入图像的纵横比可以是任意的,不需要预定义的集合、绝对位置嵌入或分区操作来适应预训练的视觉编码器。
注意这里的 cls 是全局的 Image start token,SPL 是每行结束都有的 token
Patch 对齐层: 除了粗粒度的文本监督,我们还是用预训练的视觉编码器来进行细粒度的表示学习.此外,同时建立视觉特征与视觉编码器输出的对齐空间,并将文本特征映射到语言词汇是具有挑战性的。因此我们建立了一种层级化的聚合策略,,跨越从所有的 L 层中选择的 l 层来整合中间特征(间隔 = L/l)。对于视觉 encoder,我们删除无意义的 cls 和 pad 并且记录有效的 patch 字段的二维形状.对于 EVE,我么删除 cls 和 spl 并组织为二维形状,并将序列特征重新整形为其原始的二维形状,每个形状通过自适应池化层与之前从视觉编码器记录的形状对齐。
接着,我们实现了一种按层级的交叉注意力(CA3)功能,使用最后一层的 Token 作为 Query,对应层的位置信息 Token 作为 Key 和 Value。我们对通过多层聚合获得的 Token 特征进行归一化处理,使其更好地与从视觉编码器输出的一对一归一化特征匹配,并使用均方误差(MSE)损失来优化对齐。这样的操作“隐式”地将带有绝对位置嵌入的视觉编码器(固定分辨率、固定纵横比)压缩到仅解码的 EVE 框架中(灵活分辨率、任意纵横比),从而增强了过于简单的字幕忽略的视觉感知能力。