
632 字
3 分钟
[[CLIP.pdf|CLIP]]
从自然语言监督中学习可转移的视觉模型
Abstract
目前的 sota 的计算机视觉系统在一组被事先定义好的目标分类中进行训练,这种受限的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。我们证明了预测图像与哪个描述相匹配的方法是高效的并且达到了 SOTA 的效果.预训练后,模型能够使用自然语言来引用到视觉概念,使得模型可以零样本转移到下游任务汇总
Approach
Natural Language Supervision
我们的核心理念就是从自然语言的监督中学习感知,从自然语言中学习具有如下几个优势: 自然语言的扩展性强,不需要注释以经典的机器学习兼容形式出现,而是可以大量的从网络中获取监督学习.
常规的图像分类模型往往都基于有类别标签的图像数据集进行全监督训练,例如在 Imagenet 上训练的 Resnet,Mobilenet,在 JFT 上训练的 ViT 等。这往往对于数据需求非常高,需要大量人工标注;同时限制了模型的适用性和泛化能力,不适于任务迁移。而在我们的互联网上,可以轻松获取大批量的文本 - 图像配对数据。Open AI 团队通过收集4 亿(400 million)个文本 - 图像对((image, text) pairs)**以用来训练其提出的 CLIP 模型。文本 - 图像对的示例如下:

模型架构
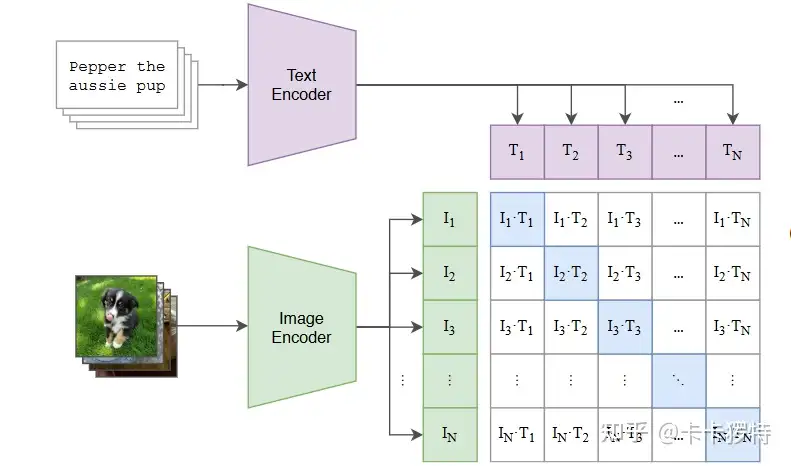
主要包括两个部分,分别是文本编码器和图像编码器,这里的文本编码器用的是 Text Transformer,Image Encodr 是 ViT
对于训练
- 一个 batch 有 N 个图像 - 文本对,将 N 个文本 T 先编码,假设每个文本被编码为长度为 dt 的一纬向量,这个 batch 的 text 输出为 ,shape 为 (n,dt).同样图像 I 为 (n,di)
- 将他们一一对应,标记为正样本,对不上的标记为负样本,这样就有了 N 个正例和 N^2-N 个负例,
- 计算余弦相似度 ,相似度越大,表明他们之间的关系越强,也就是训练目标就是最大化 N 个正样本的余弦,最小化负样本的余弦
分类
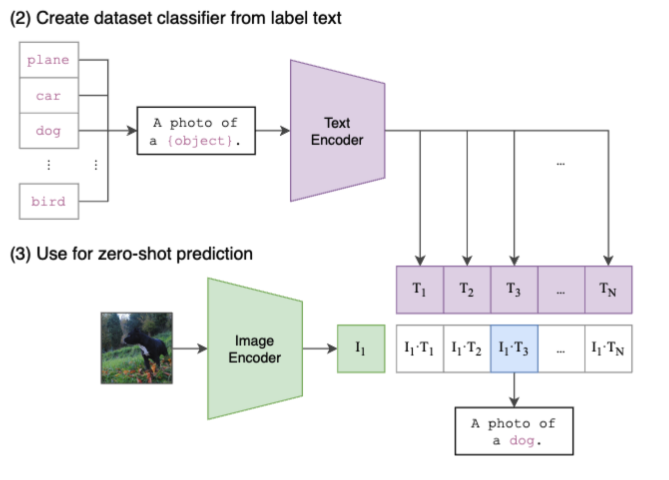
如上图,非常简单