-7561599.D_DtiG-O_ONURN.webp)

https://zhuanlan.zhihu.com/p/677607581
强化学习概述
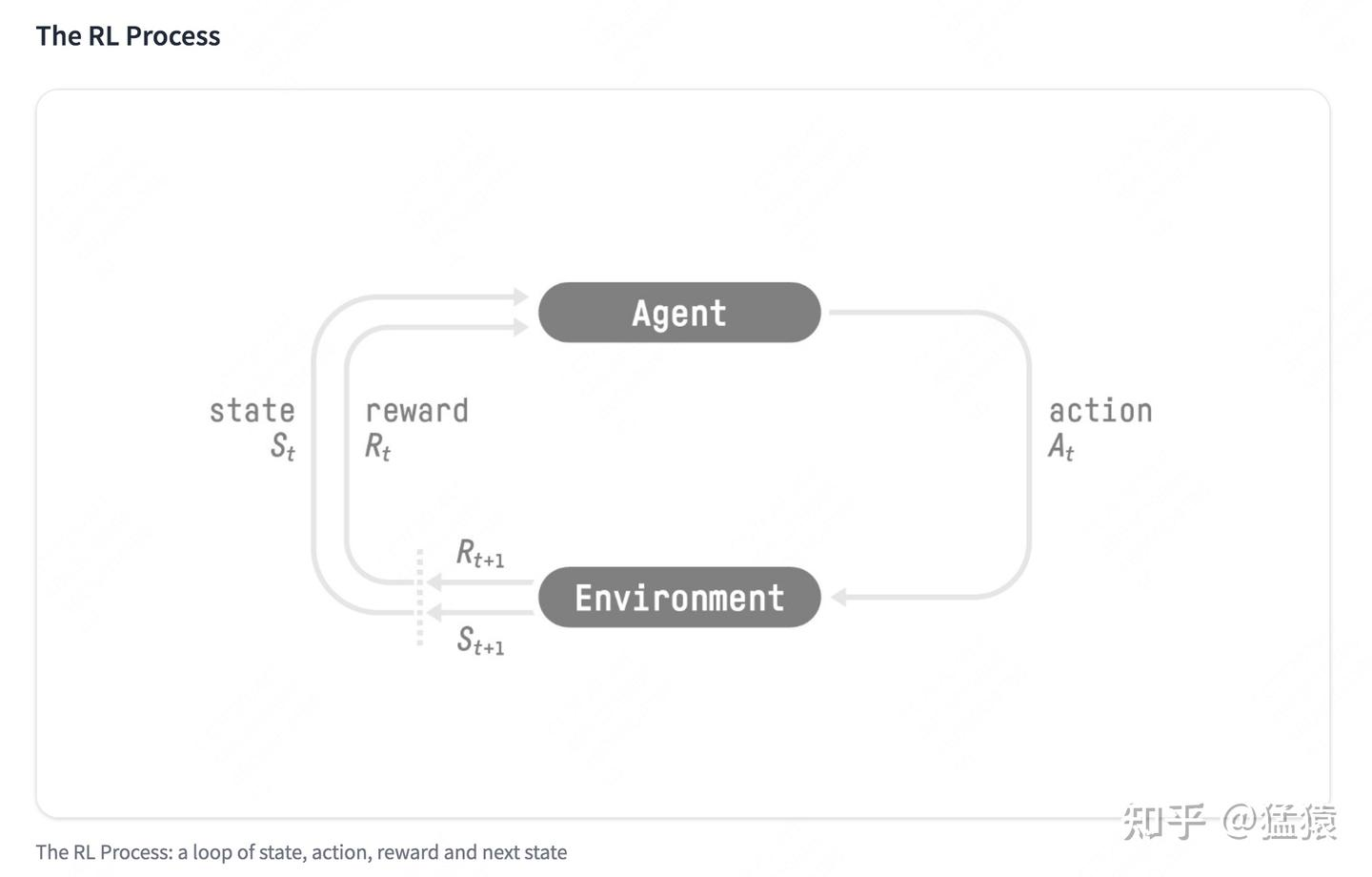
对于强化学习,有俩个实体,智能体和环境,俩实体的交互
- 状态空间 S:S 即为 State,指环境中所有可能状态的集合
- 动作空间 A:A 即为 Action,指智能体所有可能动作的集合
- 奖励 R:R 即为 Reward,指智能体在环境的某一状态下所获得的奖励。
价值函数
是模型进入状态 的及时奖励,但是只看当前似乎目光短浅了,因此我们需要考虑未来收益,也就是
其中:
- 是折扣因子
- 是未来收益
我们把强化学习的部分带入 NLP 中,那么智能体、环境、状态动作都是什么呢?
我们希望给模型一个 prompt,让模型产生符合人类喜好的回复,而 LLM 的 token 是一个个蹦出来的。
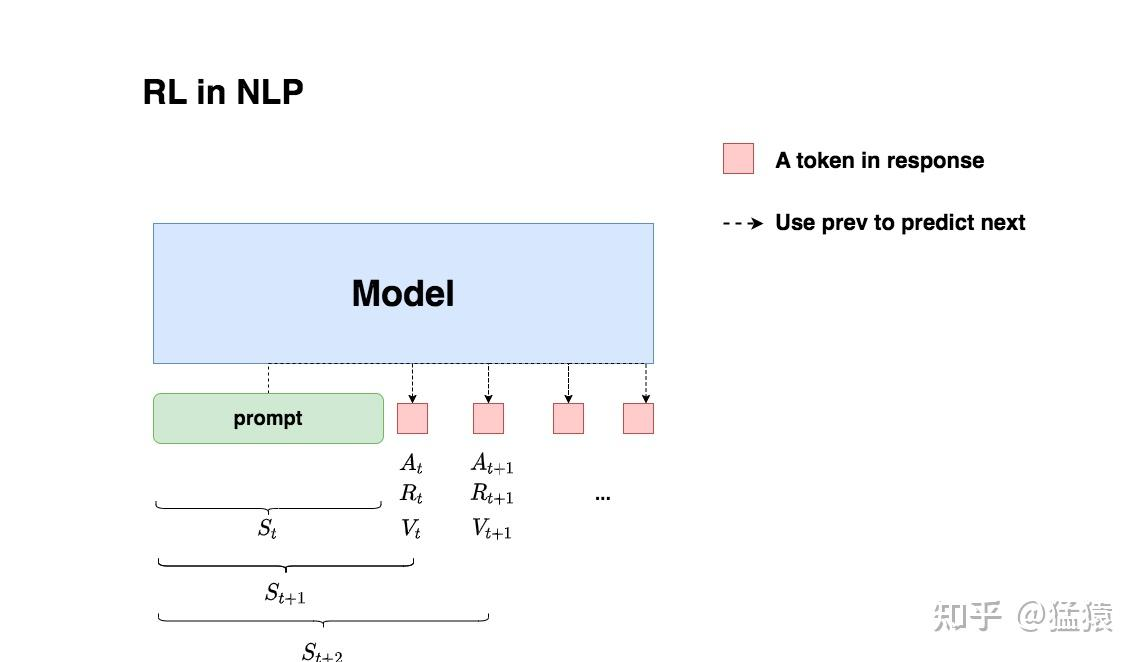
- 我们给模型一个 prompt,希望他能给出符合人类的 response
- 再 t 时刻,llm 根据上下文给出一个 token,也就是动作 。动作空间也就是词表
- 再 t 时刻,模型给出 token 对应收益 ,总收益 。
RLHF 的 4 个角色
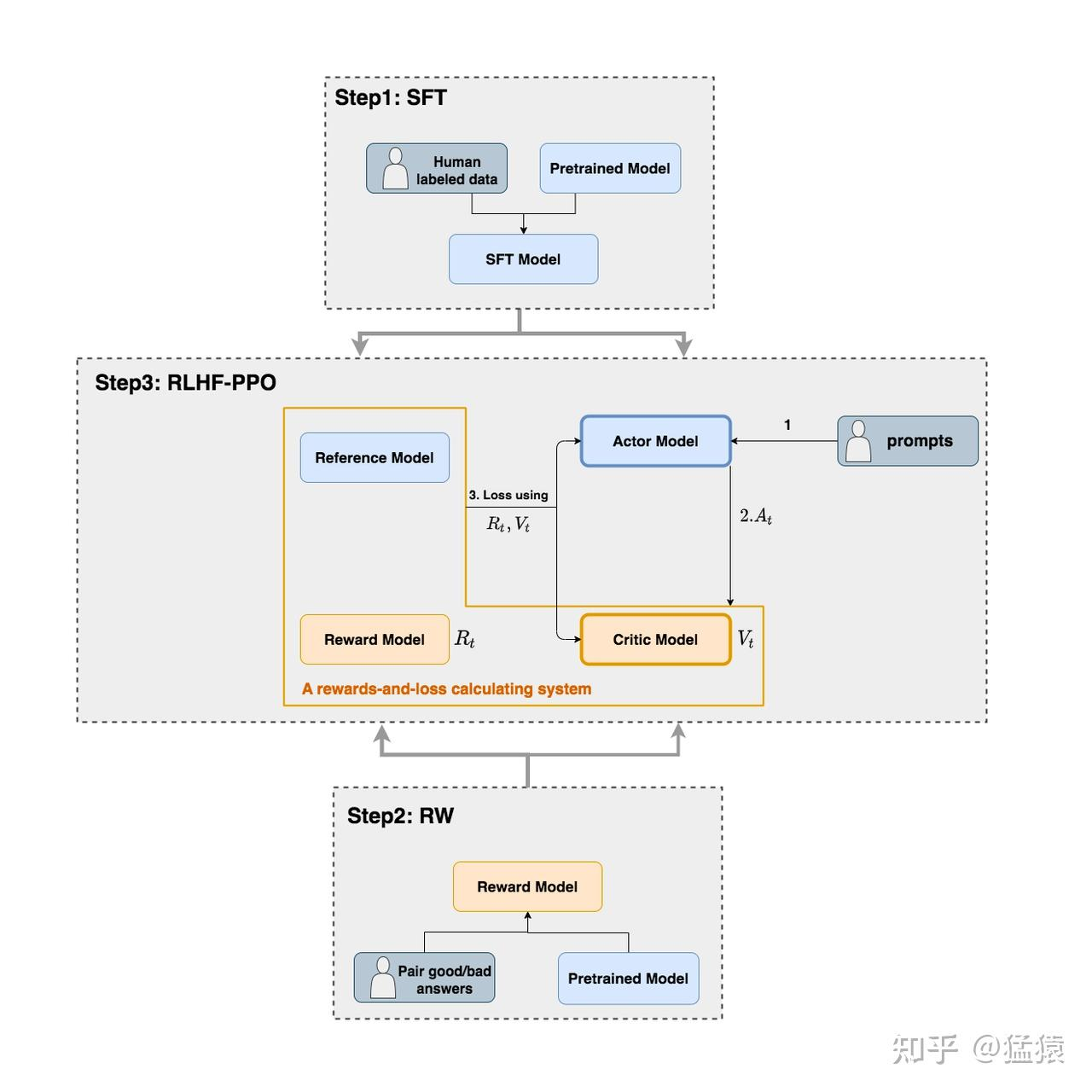
在 RLHF 中一个有 4 个重要角色,
- Actor Model:演员模型,这就是我们想要训练的目标语言模型
- Critic Model:评论家模型,它的作用是预估总收益
- Reward Model:奖励模型,它的作用是计算即时收益
- Reference Model:参考模型,它的作用是在 RLHF 阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)
- Actor/Critic Model在 RLHF 阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
- Critic/Reward/Reference Model 共同组成了一个“奖励 -loss”计算体系
参考模型
参考模型和 Actor 模型一般用的都是同一个 SFT 得到的模型,他是怎么防止模型训歪的呢?也就是我们希望训练得到的模型能达到人类的喜好但又不和 SFT 模型差别过大,也就是希望俩模型的分布尽可能的相似(也就是 KL 散度)
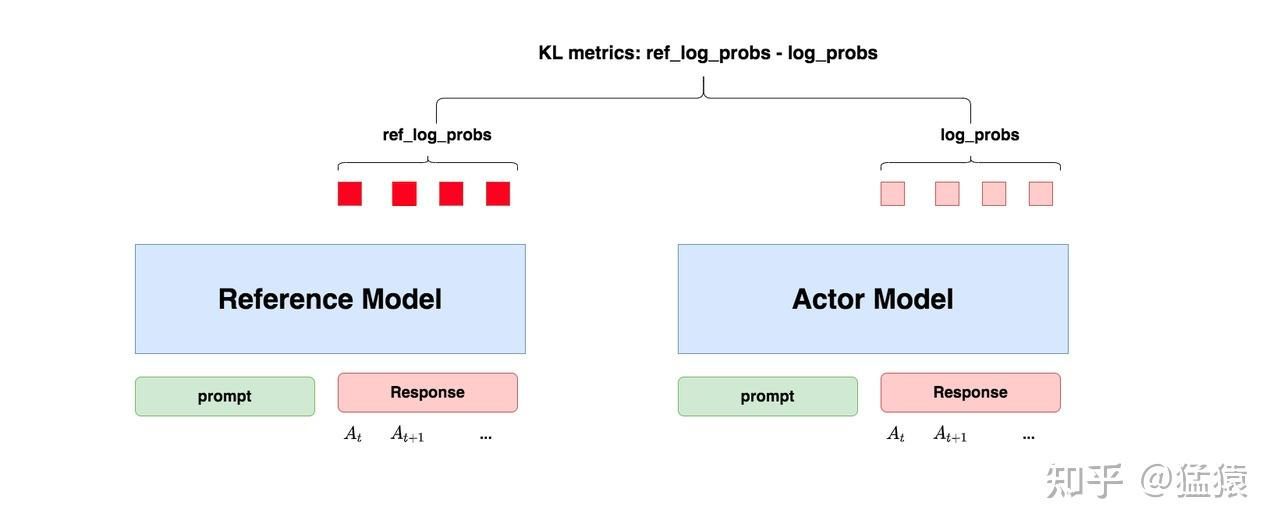
- 对于 Actor 模型,输出一个 token 会有一个 log_probs
- 对于 Ref 模型, 也会有一个 log_probs,我们标记为 ref_log_probs
- 那么这两模型的分布相似度就可以用 ref_log_probs-log_probs 来衡量
- 从直觉上,如果 ref_log_probs 很高,也就是 ref 对 act 的肯定性越高,也就是对于某个 ,输出某个 的概率高 ,
- 从 KL 散度上,,这里是近似
评论家模型
评论家用来预测总收益 ,他嗯需要做参数更新。
[!tip] 为什么要训练这个模型? 答:因为我们再训练的时候无法从上帝视角给出总收益,只能去预测
所以总结来说,在 RLHF 中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)
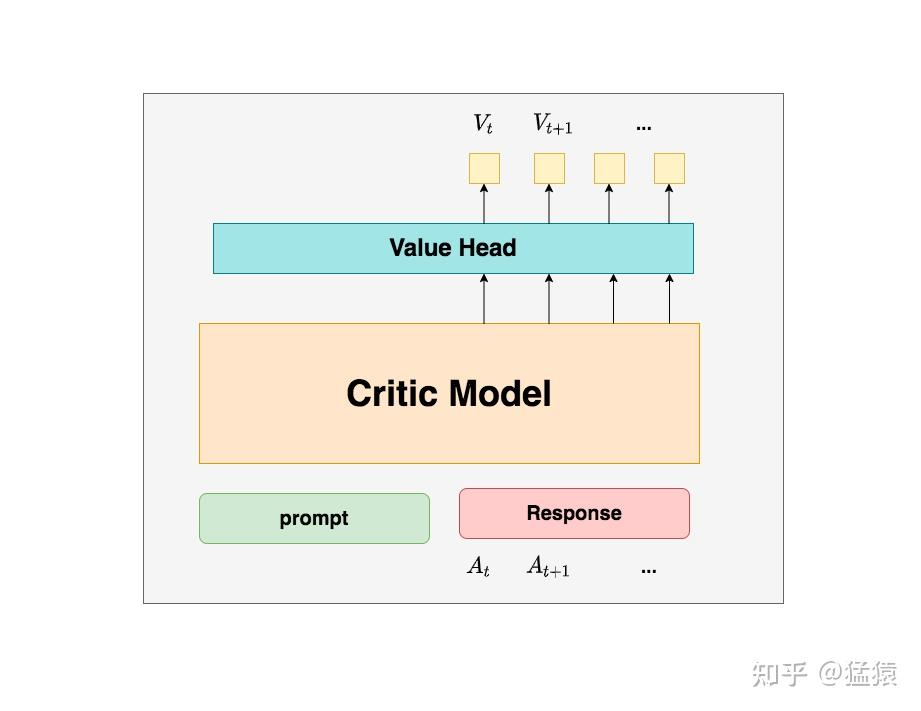
对于评论家模型,其模型架构与 actor 也类似,就是最后一层加了个线性层将输出映射为值
奖励模型
奖励模型用于计算 token 的及时收益,他是冻结的。
为什么 Critic 模型要参与训练,而同样是和收益相关的 Reward 模型的参数就可以冻结呢?
因为 Reward 模型站在上帝视角
- 第一点,Reward 模型是经过和“估算收益”相关的训练的,因此在 RLHF 阶段它可以直接被当作一个能产生客观值的模型。
- 第二点,Reward 模型代表的含义就是“即时收益”,你的 token 已经产生,因此即时收益自然可以立刻算出。
Loss 计算
再前面我们已经了解了 RLHF 的框架以及角色,下面我们计算 loss。因为 actor 和 critic 模型都会更新,因此我们需要 2 个 loss(Actor 和 Critic)
Actor Loss
actor 接收到上下文 St,给出 token ,Critic 根据 St,At,给出总收益 Vt,那么 actor_loss 就是
引入优势
在开始讲解之前,我们举个小例子:
假设在王者中,中路想支援发育路,这时中路有两种选择:1. 走自家野区。2. 走大龙路。
中路选择走大龙路,当她做出这个决定后,Critic 告诉她可以收 1 个人头。结果,此刻对面打野正在自家采灵芝,对面也没有什么苟草英雄,中路一路直上,最终收割 2 个人头。
因为实际收割的人头比预期要多 1 个,中路尝到了甜头,所以她增大了“支援发育路走大龙路”的概率。
这个多出来的“甜头”,就叫做“优势”(Advantage)。
对于 RL 任务,如果 critic 对 At 的总收益预测为 Vt,但实际收益是 ,那么优势就是实际收益 - 预测收益