
667 字
3 分钟
[[MachineLearning/NLP/预训练大模型/Agent/MMedAgentg.pdf|MMedAgentg]]
Abstract
最近,基于大模型的 agent 被开发出来根据用户的输入选择合适的模型作为工具,但是医学上较少,因此我们设计了 MMedAgent
Introduction
虽然 MLLM 获得了很大的成功,但是在处理不同模态的图片的任务时存在局限,扩展性差而且不能提供很好的回答.
一种应对方法就是使用 AI Agent,就是一种能够理解人类指令并且集成了多种的工具的模型,能够理解任务并且选择合适的模型来进行执行.我们开发的 MMedAgent 能够: 分类,分割,MRG,检索增强等.
我们为每个任务选择了目前的 SOTA 的方法,并且开发了一个数据集来教模型进行人物选择.我们方法的核心是通过视觉指令调整进行端到端的训练方案
- 我们开发了第一个医疗 AI 智能体能无缝的处理多种任务
- 我们构建了第一个开源的指令微调多模态医学数据集
- 适应多模态的医疗工具
Related Work
AI 智能体是一中能够根据环境感知和用户的指令来完成用户任务的系统,最近的模型使用 MLLM 来理解多模态输入并且调用合适的工具来进行决策.
MMedAgent
MMeDAgent 是一个基于 MLLM 的系统,包括一个指令微调的多模态大语言模型作为行动计划器和结果聚合器,和一系列的医学工具,每个都专注于一个特定的领域.
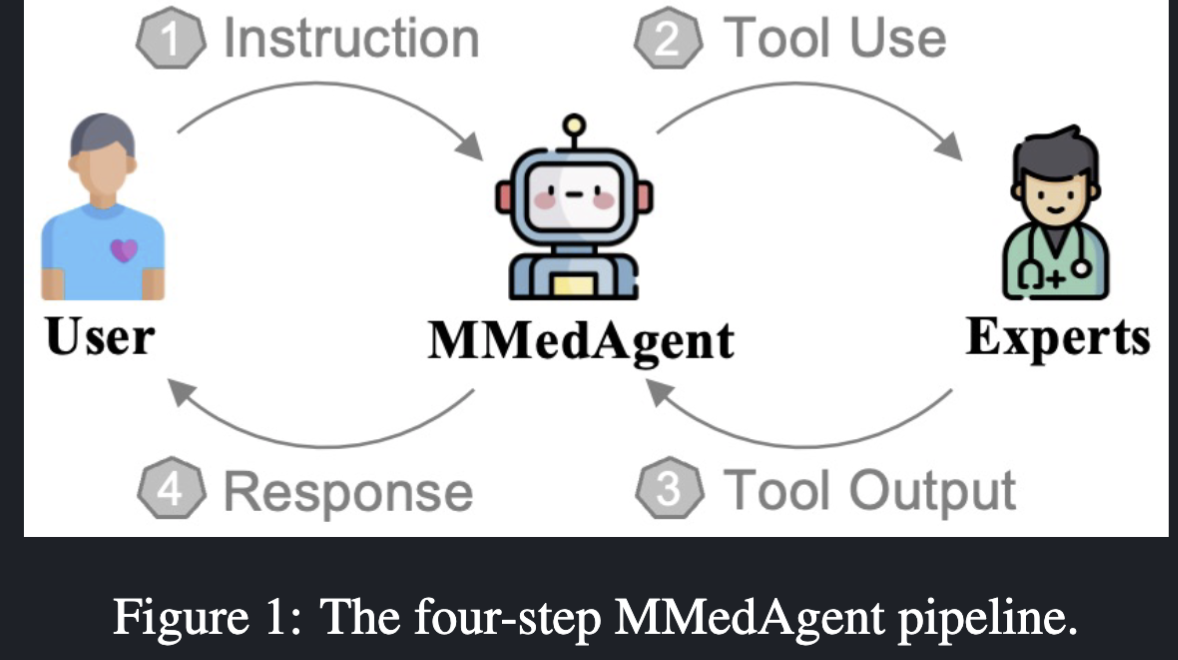
Workflow
MMeDAgent 学习了一系列的多模态医学工具,让 MLLM 的能力能够完成一系列的医学任务.
- 人类提供指令 X 和医学图像
- 大模型生成一系列的任务指令提示什么任务来被执行
- 工具处理了 I 并且输出 X_result
- 模型输出最终的结果给用户
指令微调
为了让 MMedAgent 能够充当任务决策七和结果聚合器,我们设计了一系列的 dataaset
当接受到了用户的输如 MEEdAgent 生成 3 个组件作为输出
- Thoughts: 识别当前的模型是否能够处理这个问题或者是否需要外部工具,如果需要就选择合适的工具
- Actions: 执行一系列的 API 调用
- Value: 提供自然语言回复. 在这一轮他选择了工具.第二轮中,它表示处理用户初始请求的最终输出 也就是第一轮处理行不行,第二轮才是正式处理
[[MachineLearning/NLP/预训练大模型/Agent/MMedAgentg.pdf|MMedAgentg]]
https://f1yingwhite.github.io/posts/machinelearning/nlp/预训练大模型/agent/mmedagentpdf/