
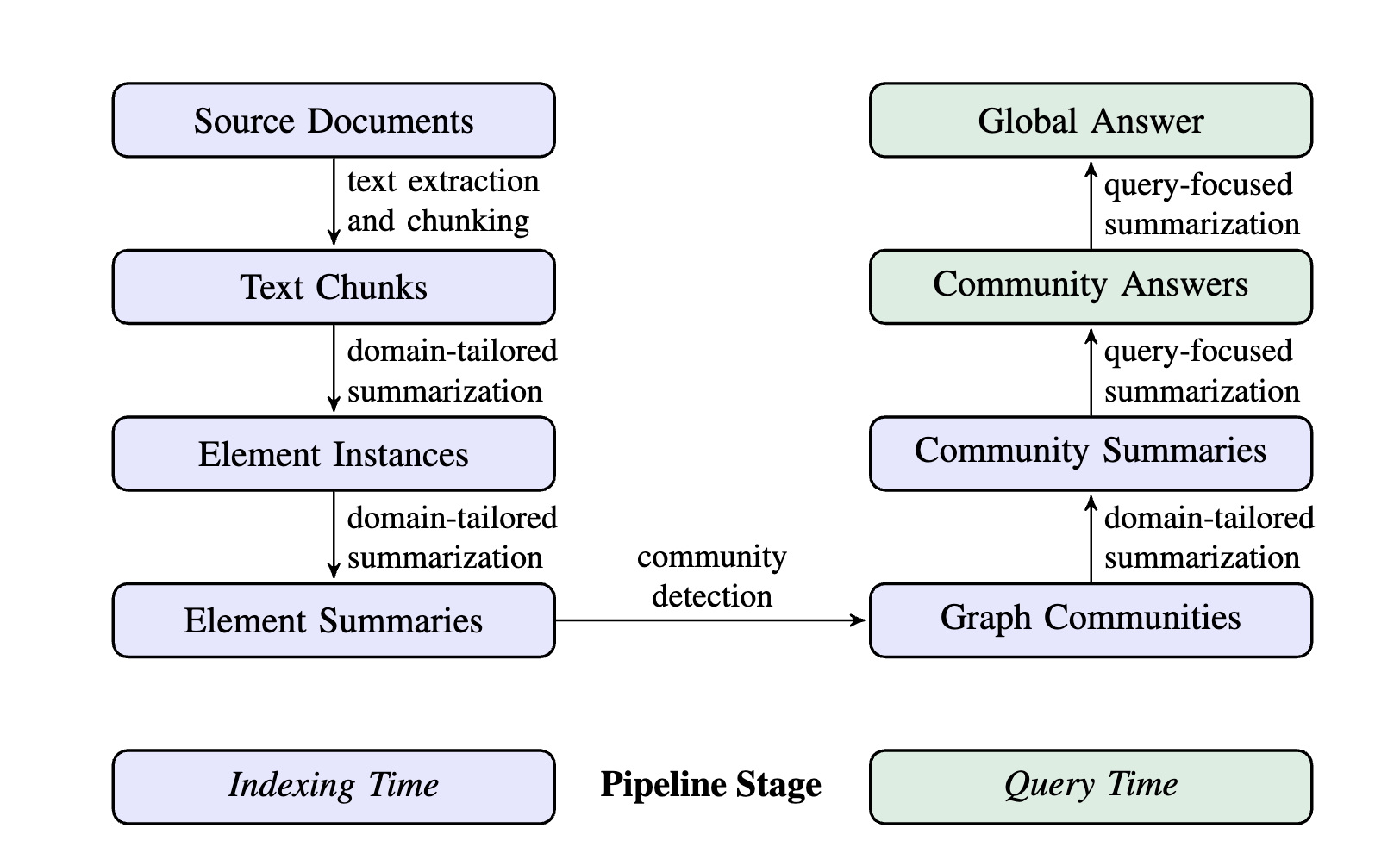
先前的 RAG 算法无法回答例如“这个图谱的主题是什么”这样无法被直接检索的任务,为了把不同的方法的优势结合起来,我们创建了一个在私有语料库上进行问答的 graphrag 方法。该方法分为两步:首先从源文档中导出实体知识图,然后为所有紧密相关的实体组预生成社区摘要。给定一个问题,每个社区摘要用于生成部分响应,然后在最终响应中再次总结所有部分响应。
rag 是在整个数据集上回答用户问题的方法,即这些答案包含在文本区域的局部,而文本区域的检索为生成任务提供了充分的基础.而更适合的方法是基于查询的总结(QFS),他生成的是抽象摘要而不是简单的串联摘录。虽然 transformer 架构的模型带来了很大的提升,但是在整个语料库中以查询为重点的抽象总结仍然是一个巨大的挑战。由于 llm 上下文的限制,很可能会导致部分信息的丢失。
在本文中我们提出了一种基于 LLM 全局总结知识图谱的 rag 算法。与利用图索引的结构化检索和遍历能力的相关工作(第 4.2 小节)不同,我们将重点放在图在这方面以前未曾探索过的特质上:图的模块性,以及社群检测算法
文档 ->text Chunks
首先把文档分块,然后接下来每一块都被传送到 llm 中来提取图的各种元素。较长的文本块需要较少的 LLM 调用来进行此类提取,但由于 LLM 上下文窗口较长,召回率会下降
文本块 ->元素实体
此步骤是从文本块中提取图的节点和边。我么使用一个多步的 llm 首先提取所有的实体,包括名字,类型和描述,再识别他们之间的关系。此外我们还使用了
元素实体 ->实体总结
使用 llm 提取了元素已经是一次抽象总结了,为了把实体级别的抽象转换为全局的抽象需要在这些实体上进行额外的 llm 总结
在这一阶段,一个潜在的担忧是,LLM(大语言模型)可能无法始终以相同的文本格式提取对同一实体的引用,从而导致重复的实体元素,进而在实体图中产生重复的节点。但是因为所有的紧密相连的社区都在后续步骤中被检测和总结,并且考虑到 LLM 能够理解多种名称变体背后的共同实体,只要所有变体都与一组共享的紧密相关实体有足够的连接性,我们的整体方法对这种变体具有鲁棒性。
实体总结 ->图社区
在前一步创建的索引可以建模为一个同质无向加权图,其中实体节点通过关系边相连,边的权重表示检测到的关系实例的归一化计数。基于此类图,可以使用多种社区发现算法将图划分为社区,使得社区内的节点之间的连接比与其他节点的连接更紧密。在我们的流程中,我们选择Leiden 算法(Traag 等,2019),因为它能够高效地恢复大规模图的层次社区结构(见图 3)。该层次结构的每一层都提供了一个覆盖图中所有节点的互斥且穷尽的社区划分,从而实现分而治之的全局摘要。
- 叶级社区的元素摘要(节点、边、协变量)按优先级排序,并依次添加到 LLM 的上下文窗口中,直到达到token 限制。优先级规则如下:按源节点和目标节点的度数之和(即整体重要性)降序排列每条社区边,并依次添加源节点描述、目标节点描述、相关协变量和边的描述。
- 高层级社区:如果所有元素摘要都能适应上下文窗口的 token 限制,则按照叶级社区的方法处理,汇总社区内的所有元素摘要。否则,按元素摘要的 token 数量降序排列子社区,并逐步用子社区摘要(较短)替换其关联的元素摘要(较长),直到满足上下文窗口的限制。
Community Summaries → Community Answers → Global Answer
给定一个用户查询,社区能够通过多步来生成一个最终回答。多级社区意味着能够从不同级别来回答用户的问题,带来了某一级是否拥有足够的信息的问题。 给定一个社区级别,全局回答流程如下:
- 准备社区中介