-7561599.D_DtiG-O_ONURN.webp)

823 字
4 分钟
混合专家模型
总结
混合专家模型 (MoEs):
与稠密模型相比, 预训练速度更快
与具有相同参数数量的模型相比,具有更快的 推理速度
需要 大量显存,因为所有专家系统都需要加载到内存中
在 微调方面存在诸多挑战,但近期的研究表明,对混合专家模型进行 指令调优具有很大的潜力。
什么是混合专家模型
模型的规模往往是模型性能提升的关键,而在资源有限的情况下,用更少的训练步数训练一个更大的模型,往往比更多步数训练一个小模型更好
MoE 的一个显著优势是它能够在远小于稠密模型的计算资源下进行有效的训练,因此可以扩大模型的规模并且更快的达到效果。
那么什么是 MoE 呢?混合专家模型是一种基于 Transformer 架构的模型,主要有良个关键部分组成
- 稀疏 MoE 层:这些层替代了传统的 Transformer 的前馈网络(FFN),MoE 层包含若干个专家,每个网络是一个独立的神经网络,一般也是 FFN,他们甚至也可以是 MoE
- 门控制或者路由:这个部分用于决定哪些令牌 (token) 被发送到哪个专家。比如下图中,More 可能被转发到第二个专家,而 Parameters 转发到第一个专家,有时一个令牌可以被转发到多个专家,令牌的路由方式是 MoE 的一个训练点,他是一个网络
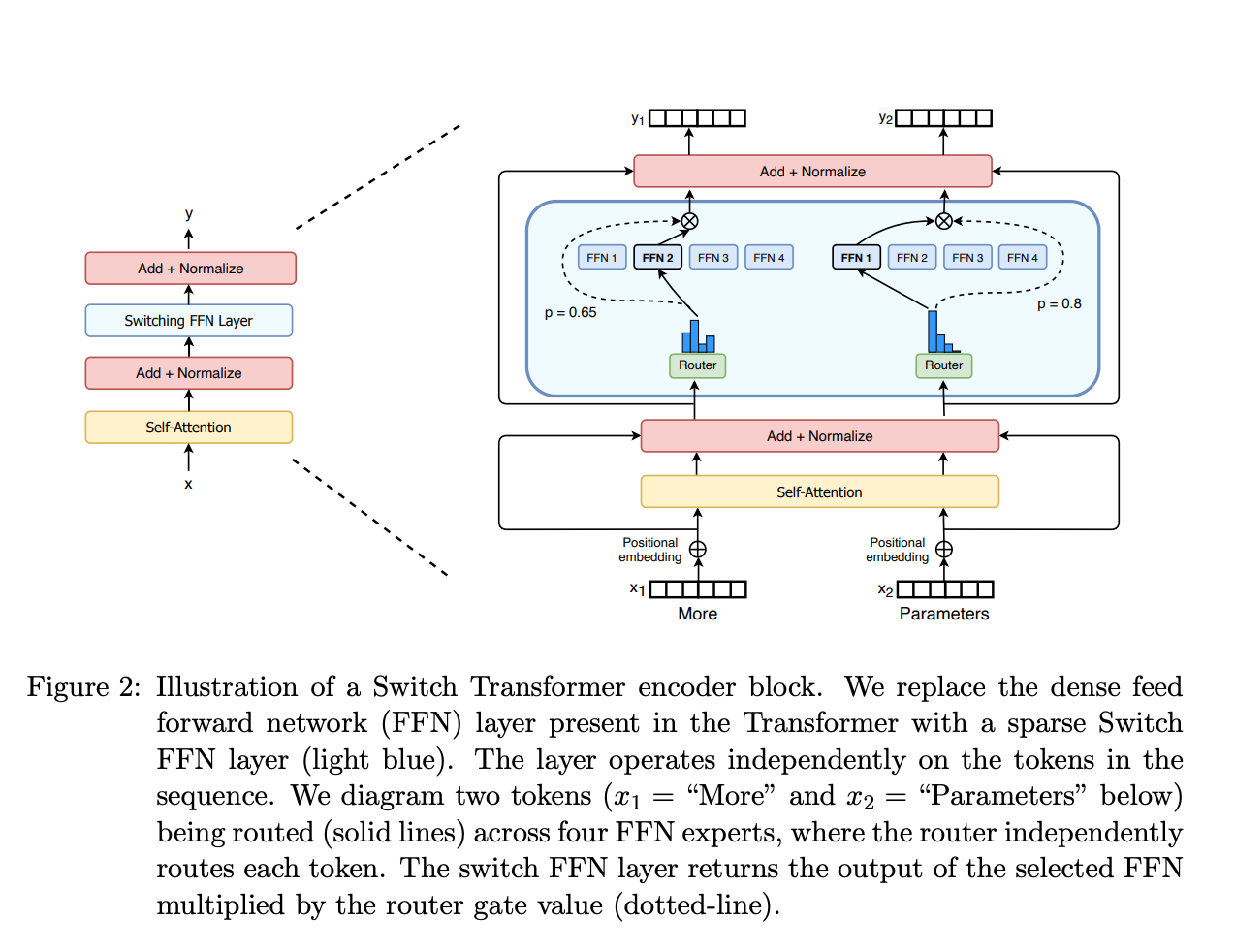
该网络的优势在于:推理快,与训练高效,但是
- 训练挑战:虽然预训练高效,但是微调阶段泛化能力差,容易过拟合
- 推理挑战:虽然只需要一部分的参数,但是要把所有的参数加载到内存,可能需要更大的显存
什么是稀疏性
稀疏性采用了条件计算的思想,在稠密模型中,所有的参数都会被使用,但是系数模型允许我们对整个系统的特定部分进行计算,这意味着只有部分参数会被调用和执行。
条件计算的概念使得在不额外增加计算负担的情况下扩展模型成为了可能,但是稀疏性仍然带来了挑战,比如经管大批量的模型有利于提升性能,但是大哥数据通过激活的专家时,实际的批量可能会减少.比如,假设我们的输入批量包含 10 个令牌, 可能会有五个令牌被路由到同一个专家,而剩下的五个令牌分别被路由到不同的专家。这导致了批量大小的不均匀分配和资源利用效率不高的问题。
我们可以使用一个可学习的门控制网络 G 来决定输入的那一部分发送给哪些专家
这种设置下,所有的专家都会进行运算,但是我们可以控制 Gx 为 0,也就是使用 softmax 来充当 G(x)