-7561599.D_DtiG-O_ONURN.webp)

681 字
3 分钟
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
当前的 MLLM 通常使用一个 visual encoder 来帮助 llm 理解图片,在图像生成领域也有自回归或者使用 diffusion 的方法。但是这些方法通常依赖外部的 DiffusionModel,无法直接生成图片。多模态理解和生成任务所需的表示形式存在显着差异。在多模态理解任务中,视觉编码器的目的是提取高级语义信息(例如,图像中的对象类别或视觉属性)。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理,因此其表征粒度主要聚焦于高维语义表示。相比之下,在视觉生成任务中,重点在于生成局部细节并保持图像的全局一致性,此时的表征需要一种低维编码,以支持对精细空间结构和纹理细节的表达。将这两类任务的表征统一到同一空间中,会导致表征冲突与性能权衡,因此,现有的多模态理解与生成统一模型往往在多模态理解性能上做出妥协,明显落后于当前最先进的多模态理解模型。
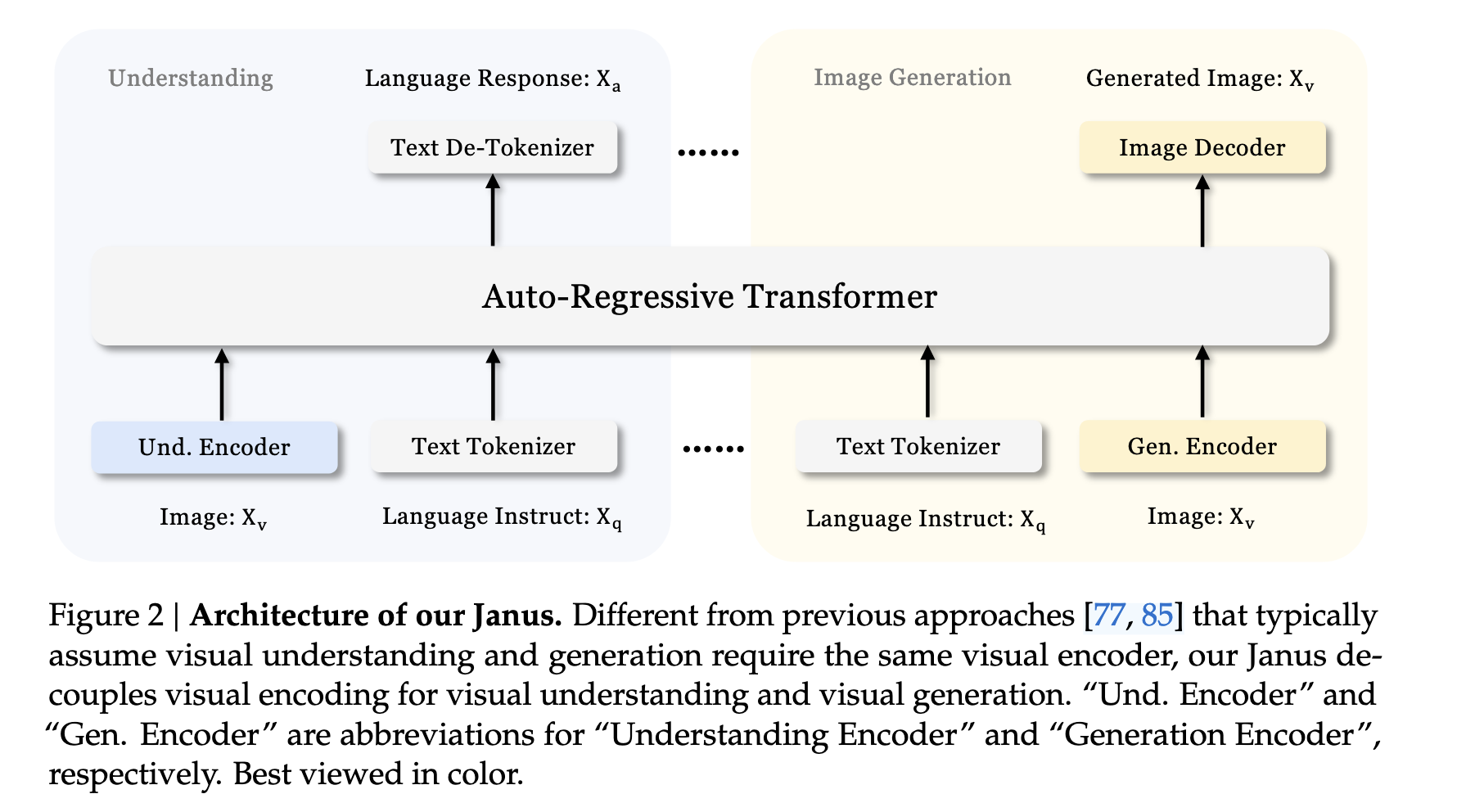
Janus 的架构如图所示。针对纯文本理解、多模态理解和视觉生成任务,我们采用各自独立的编码方式将原始输入转换为特征,然后由一个统一的自回归 Transformer 进行处理。
具体而言:
- 对于文本理解任务,我们使用大语言模型(LLM)内置的分词器将文本转换为离散 ID,并获取每个 ID 对应的特征表示。
- 对于多模态理解任务,我们采用 SigLIP 编码器从图像中提取高维语义特征。这些特征原本是二维网格形式,被展平为一维序列,并通过一个理解适配器(understanding adaptor)映射到 LLM 的输入空间。
- 对于视觉生成任务,我们使用 VQ 分词器将图像转换为离散 ID 序列;该序列展平为一维后,通过一个生成适配器(generation adaptor)将每个 ID 对应的码本嵌入映射到 LLM 的输入空间。
随后,我们将上述各类特征序列拼接成一条多模态特征序列,输入到 LLM 中进行统一处理。
- 在文本理解和多模态理解任务中,使用 LLM 自带的预测头进行文本预测;
- 在视觉生成任务中,则采用一个随机初始化的预测头进行图像标记(ID)的预测。
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
https://f1yingwhite.github.io/posts/machinelearning/nlp/llm/mllm/wujanusdecouplingvisual2024/