-7561599.D_DtiG-O_ONURN.webp)

372 字
2 分钟
Qwen2.5-VL Technical Report
Qwen2.5-VL Technical Report
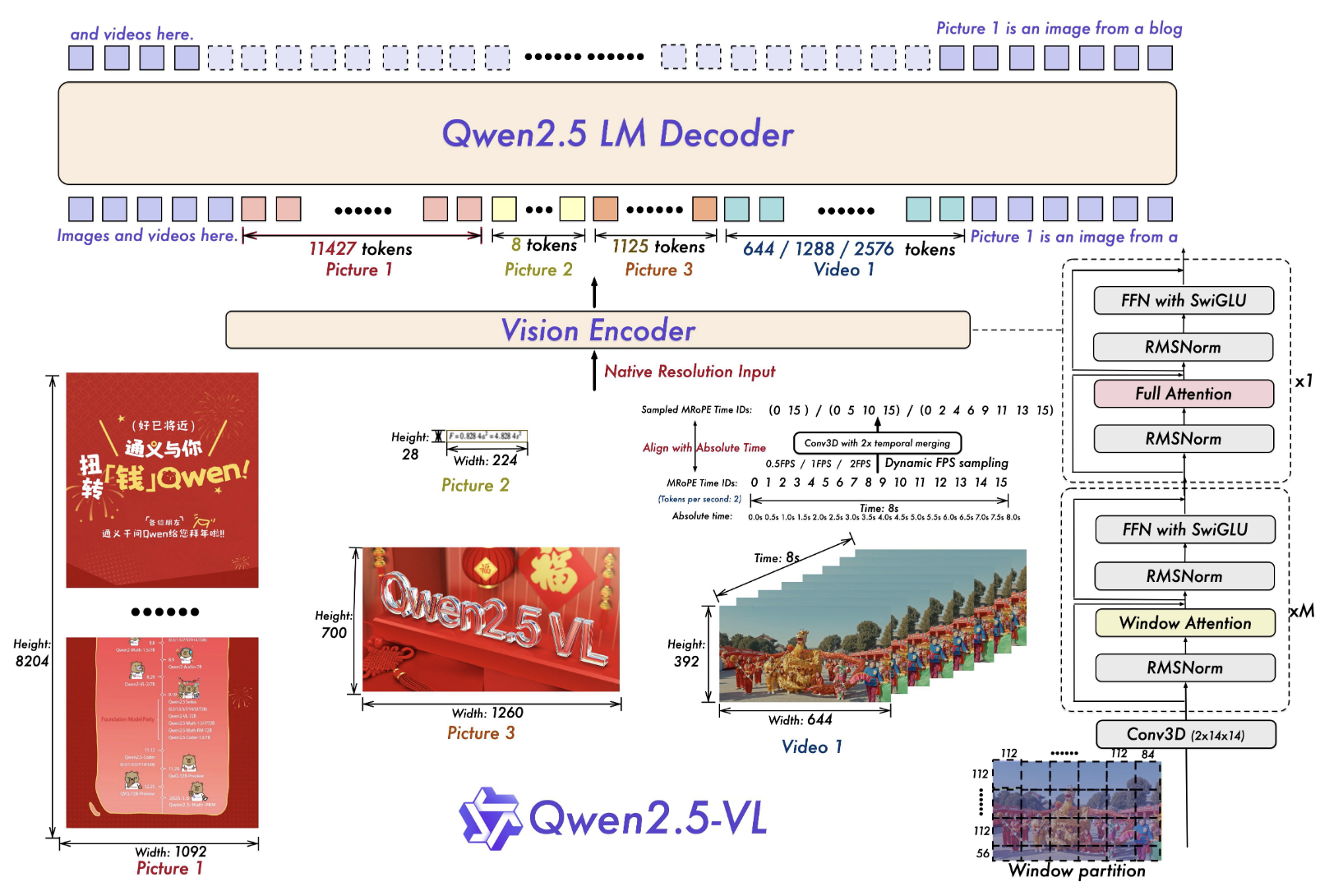
Qwen2.5-VL 的架构如上,主要用于图形和视频的理解
模型架构
Qwen2.5VL 的模型架构主要有 3,VisionEncoder(ViT),LLM(qwen2.5) 和 MLP-based Vision-Language Merger
其中 MLP 是用来降低 ViT 特征的维度。并未直接使用 ViT 提取的 patch 特征,而是首先将空间上相邻的四个图像块特征进行分组,将这些分组后的特征拼接起来,并通过一个两层的 MLP 将其投影到与 LLM 中所用文本嵌入维度对齐的空间中。该方法不仅降低了计算开销,还提供了一种灵活的方式,能够动态压缩不同长度的图像特征序列。
ViT 是核心部分,这里的 ViT 从新开始训练,为了保持 ViT 和 LLM 架构的部分的一致性,他吧 norm 层改为了 RMSNorm,吧激活改成了 SwinGLU,最重要的是,原始的 ViT 想要外推,需要的时间复杂度是 ,因此采用了无重叠的 window attention,patchsize 为 14,图像被 resize 为 24 的倍数,window 的 size 为 112(也就是 8x8 的窗口大小),对于不够 112 的地方保持不变,此外,还提出了 MRoPE(也就是三维的 RoPE),通过时间帧的真实长度(也就是第几秒而不是第几帧,保持了不同 FPS 视频的一致性),有 heigh,weight 和 time 三个维度,对于 text,保持位置 id 一致,此时退化为 1D RoPE;对于图像,保持 time 一致
Qwen2.5-VL Technical Report
https://f1yingwhite.github.io/posts/machinelearning/nlp/llm/mllm/baiqwen25vltechnicalreport2025/