-7561599.D_DtiG-O_ONURN.webp)

Join
现在我们有一个 team 模型
from sqlmodel import Field, SQLModel, create_engine
class Team(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) headquarters: str
class Hero(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: int | None = Field(default=None, index=True)
team_id: int | None = Field(default=None, foreign_key="team.id")在 field 中,我们定义了一个外键.
对于查询,我们可以使用如下命令进行连表查询
def select_heroes(): with Session(engine) as session: statement = select(Hero, Team).where(Hero.team_id == Team.id) for hero, team in results: print("Hero:", hero, "Team:", team)另一种方式是使用 join,在 SQLModel (实际上是 SQLAlchemy) 中,当使用 .join() 时,因为我们在创建模型时已经声明了 foreign_key,所以我们不需要传递 ON 部分,它是自动推断的。
def select_heroes(): with Session(engine) as session: statement = select(Hero, Team).join(Team).where(Team.name == "Preventers") results = session.exec(statement) for hero, team in results: print("Hero:", hero, "Team:", team)关系属性
前面我们讨论了如何使用具有指向其他列的外键来管理具有管理的表中的数据库,现在我们将看到如何使用关系属性以更熟悉的方式更接近 python 的方式来处理数据库中的数据
声明关系属性
导目前为止,我们只在 select 查询的时候使用 team_id 来链接表,现在我们来为这类模型类添加 RelationShip 属性
from sqlmodel import Field, Relationship, Session, SQLModel, create_engine
class Team(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) headquarters: str
heroes: list["Hero"] = Relationship(back_populates="team")
class Hero(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: int | None = Field(default=None, index=True)
team_id: int | None = Field(default=None, foreign_key="team.id") team: Team | None = Relationship(back_populates="heroes")也许你会注意到这里的 “Hero”,在代码中的那一行,Python 解释器此时不知道任何名为 Hero 的类,如果我们将它直接放在那里,它会尝试查找但失败。😭
但是通过将它放在引号中,作为一个字符串,解释器会将其视为一个字符串,其中包含文本 "Hero"。
但是编辑器和其他工具可以看到该字符串实际上是一个类型注解,并提供所有的自动完成、类型检查等功能。🎉
什么是这些关系属性
这些新属性与字段不同,它们不直接表示数据库中的列,它们的值也不是像整数这样的单个值。它们的值是相关的实际整个对象。
因此,在 Hero 实例的情况下,如果您调用 hero.team,您将获得该英雄所属的整个 Team 实例对象。✨
例如,您可以检查一个 hero 是否属于任何 team(如果 .team 不是 None),然后打印团队的 name
def create_heroes(): with Session(engine) as session: team_preventers = Team(name="Preventers", headquarters="Sharp Tower") team_z_force = Team(name="Z-Force", headquarters="Sister Margaret's Bar")
hero_deadpond = Hero( name="Deadpond", secret_name="Dive Wilson", team=team_z_force ) hero_rusty_man = Hero( name="Rusty-Man", secret_name="Tommy Sharp", age=48, team=team_preventers ) hero_spider_boy = Hero(name="Spider-Boy", secret_name="Pedro Parqueador") session.add(hero_deadpond) session.add(hero_rusty_man) session.add(hero_spider_boy) session.commit()
session.refresh(hero_deadpond) session.refresh(hero_rusty_man) session.refresh(hero_spider_boy)
print("Created hero:", hero_deadpond) print("Created hero:", hero_rusty_man) print("Created hero:", hero_spider_boy)现在我们可以使用 relationship 来创建类了,我们甚至不需要使用 session.add(team)
读取关系
现在让我们来看如何读取关系
#旧方法def select_heroes(): with Session(engine) as session: statement = select(Hero).where(Hero.name == "Spider-Boy") result = session.exec(statement) hero_spider_boy = result.one()
statement = select(Team).where(Team.id == hero_spider_boy.team_id) result = session.exec(statement) team = result.first() print("Spider-Boy's team:", team)
# 新方法def select_heroes(): with Session(engine) as session: statement = select(Hero).where(Hero.name == "Spider-Boy") result = session.exec(statement) hero_spider_boy = result.one() print("Spider-Boy's team again:", hero_spider_boy.team)同样,现在移除关系变得更简单了
def update_heroes(): with Session(engine) as session: statement = select(Hero).where(Hero.name == "Spider-Boy") result = session.exec(statement) hero_spider_boy = result.one()
hero_spider_boy.team = None session.add(hero_spider_boy) session.commit()
session.refresh(hero_spider_boy)关系反向填充
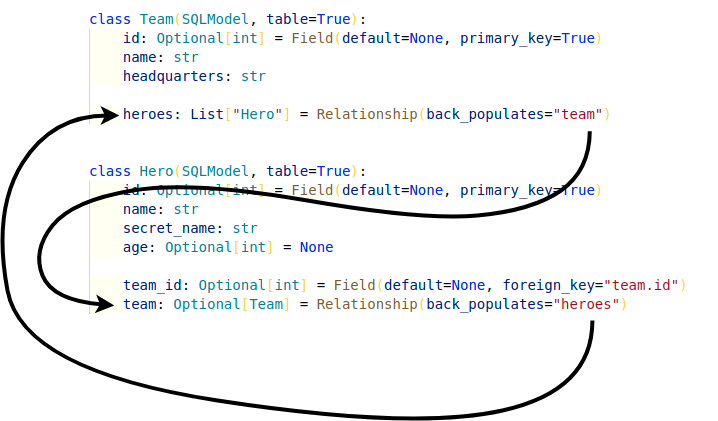
那么,每个 RelationShip() 中的 back_populates 是啥??该值是一个字符串,其中包含另一个模型类中的属性名称。它告诉 SQLModel,如果此模型中发生了更改,它应该更改另一个模型中的该属性,并且即使在会话提交之前(这将强制刷新数据)它也有效.填写了 back_populates 后,我们的代码就可以在 commit 之前更新了!
class Hero(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: int | None = Field(default=None, index=True)
team_id: int | None = Field(default=None, foreign_key="team.id") team: Team | None = Relationship(back_populates="heroes")
weapon_id: int | None = Field(default=None, foreign_key="weapon.id") weapon: Weapon | None = Relationship(back_populates="hero")
powers: list[Power] = Relationship(back_populates="hero")注意这里的 heroes 和 hero 来区分复数 (有没有用我也不知道)
多对多
现在假设一个英雄有多个团队,一个团队也有多个英雄
class HeroTeamLink(SQLModel, table=True): team_id: int | None = Field(default=None, foreign_key="team.id", primary_key=True) hero_id: int | None = Field(default=None, foreign_key="hero.id", primary_key=True)
class Team(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) headquarters: str
heroes: list["Hero"] = Relationship(back_populates="teams", link_model=HeroTeamLink)
class Hero(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: int | None = Field(default=None, index=True)
teams: list[Team] = Relationship(back_populates="heroes", link_model=HeroTeamLink)我们使用 back_populates="teams"。之前我们引用了一个属性 team,但现在我们可以有多个,所以我们在创建 Hero 模型时将其重命名为 teams。这是允许多对多关系的重要部分,我们使用 link_model=HeroTeamLink。就是这样。✨
使用额外字段链接模型
在前面的示例中,我们从未直接与 HeroTeamLink 模型交互,它全部通过自动的多对多关系进行。但是,如果我们需要有额外的数据来描述两个模型之间的链接呢?假设我们想要一个额外的字段/列来说明一个英雄是否仍然在团队中训练,或者他们是否已经在执行任务等等。
使用两个一对多关系的链接模型
处理这种情况的方法是显式使用链接模型,以便能够获取和修改其数据(除了指向 Hero 和 Team 的两个模型的外键)。
class HeroTeamLink(SQLModel, table=True): team_id: int | None = Field(default=None, foreign_key="team.id", primary_key=True) hero_id: int | None = Field(default=None, foreign_key="hero.id", primary_key=True) is_training: bool = False
team: "Team" = Relationship(back_populates="hero_links") hero: "Hero" = Relationship(back_populates="team_links")
class Team(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) headquarters: str
hero_links: list[HeroTeamLink] = Relationship(back_populates="team")
class Hero(SQLModel, table=True): id: int | None = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: int | None = Field(default=None, index=True)
team_links: list[HeroTeamLink] = Relationship(back_populates="hero")def update_heroes(): with Session(engine) as session:
# Code here omitted 👈
for link in hero_spider_boy.team_links: if link.team.name == "Preventers": link.is_training = False
session.add(hero_spider_boy) session.commit()
for link in hero_spider_boy.team_links: print("Spider-Boy team:", link.team, "is training:", link.is_training)
# Code below omitted 👇处理循环导入
但是我们想要声明的这些类型注解在 _ 运行时 _ 是不需要的。
实际上,还记得我们使用了 List["Hero"],其中 "Hero" 是一个字符串吗?
对于 Python 来说,在运行时,它仅仅是一个字符串。
因此,如果我们能够使用字符串版本添加我们需要的类型注解,Python 就不会有问题。
但是,如果我们在类型注解中只使用字符串,而不导入任何东西,编辑器就不知道我们指的是什么,并且无法帮助我们进行自动补全和内联错误。
为了解决这个问题,在 typing 模块中有一个特殊的技巧,使用一个特殊的变量 TYPE_CHECKING。
对于使用类型注解分析代码的编辑器和工具,它的值为 True。
但是当 Python 执行时,它的值为 False。
因此,我们可以在 if 代码块中使用它,并在 if 代码块内部导入内容。它们将只为编辑器“导入”,而不是在运行时导入。
from typing import TYPE_CHECKING, Optional
from sqlmodel import Field, Relationship, SQLModel
if TYPE_CHECKING: from .team_model import Team
class Hero(SQLModel, table=True): id: Optional[int] = Field(default=None, primary_key=True) name: str = Field(index=True) secret_name: str age: Optional[int] = Field(default=None, index=True)
team_id: Optional[int] = Field(default=None, foreign_key="team.id") team: Optional["Team"] = Relationship(back_populates="heroes")请记住,现在我们 _ 必须 _ 将 Team 的注解写成字符串:"Team",这样 Python 在运行时就不会出现错误。