Abstract
多尺度特征对于密集预测任务非常重要,包括目标检测,实例分割,目前的方法通常先使用分类的backbone来进行多尺度特征提取然后使用lightweight module来对特诊进行聚合,但是我们认为这样可能是不够的,因为特征融合网络分配的参数太少了,为了解决这个问题,我们提出了一种叫做cascade fusion network的架构.除了生成高纬度特征的网络,我们还使用了几个级联阶段的网络用语生成多尺度特征,每个阶段都包含一个用于特征提取的主干和一个用于特征集成的轻量化网络.这种设计让特征可以更加deep和高效的聚合在一起.
Introduction
对于大多数预测任务,主流的CNN和Transformer网络使用顺序方式并且逐渐减少特征图的大小,并根据coarsest scale的特征进行预测,但是对于许多密集预测任务,需要多尺度特征,如何高校的获得并且使用它们是任务成功的关键.
特征金字塔(FPN)和他的变体被广泛的应用在多尺度特征提取和特征融合上.通常这些网络有一个heavy backbone来提取多尺度的特征和一个轻量的特征聚合网络.
计算资源一定的情况下,如果我们希望给特征融合更多的参数,一个直观的方法是缩小主干并且扩大特征融合模块,但是这样就意味着无法从大规模预训练模型中收益,所以So how can we allocate more parameters to achieve feature fusion,while keeping a simple model architecture that can still benefit from large-scale pre-training to the greatest extent?
首先来看FPN的模型,为了融合多尺度的特征,首先使用加法把临近的特征加起来,然后使用一个3x3卷积来改变特征.我们把这两步称为特征聚合和特征transformation.显然我们可以使用更多的卷积,但是这会减少backbone的参数量.从另一个角度来看,我们是否能把特征聚合操作放到backbone里面从而使得参数可以被用来聚合特征 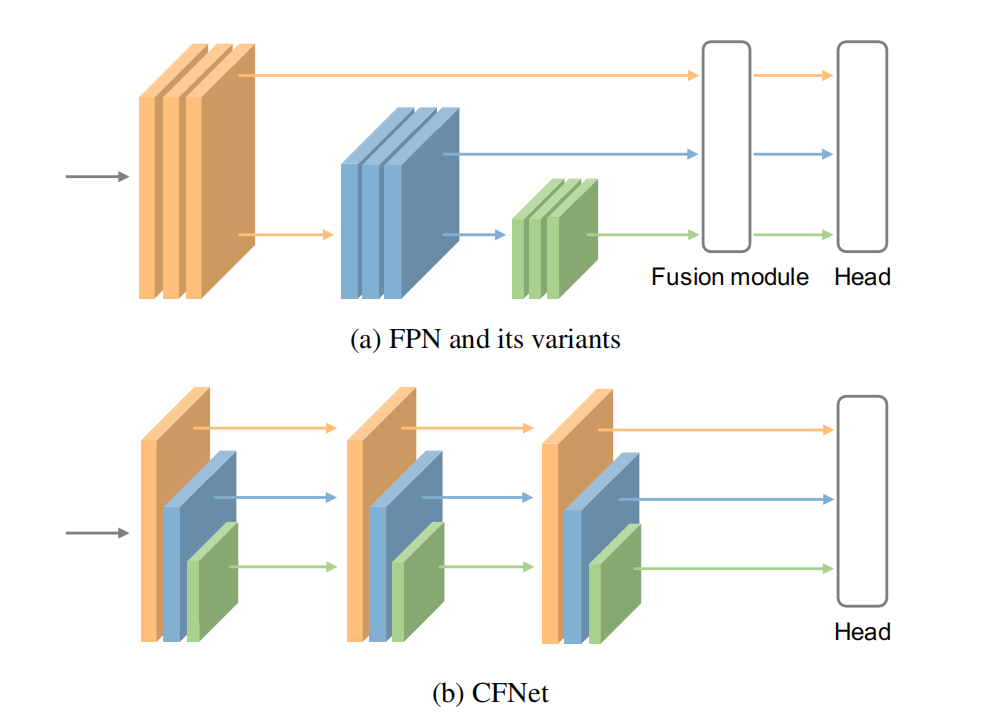
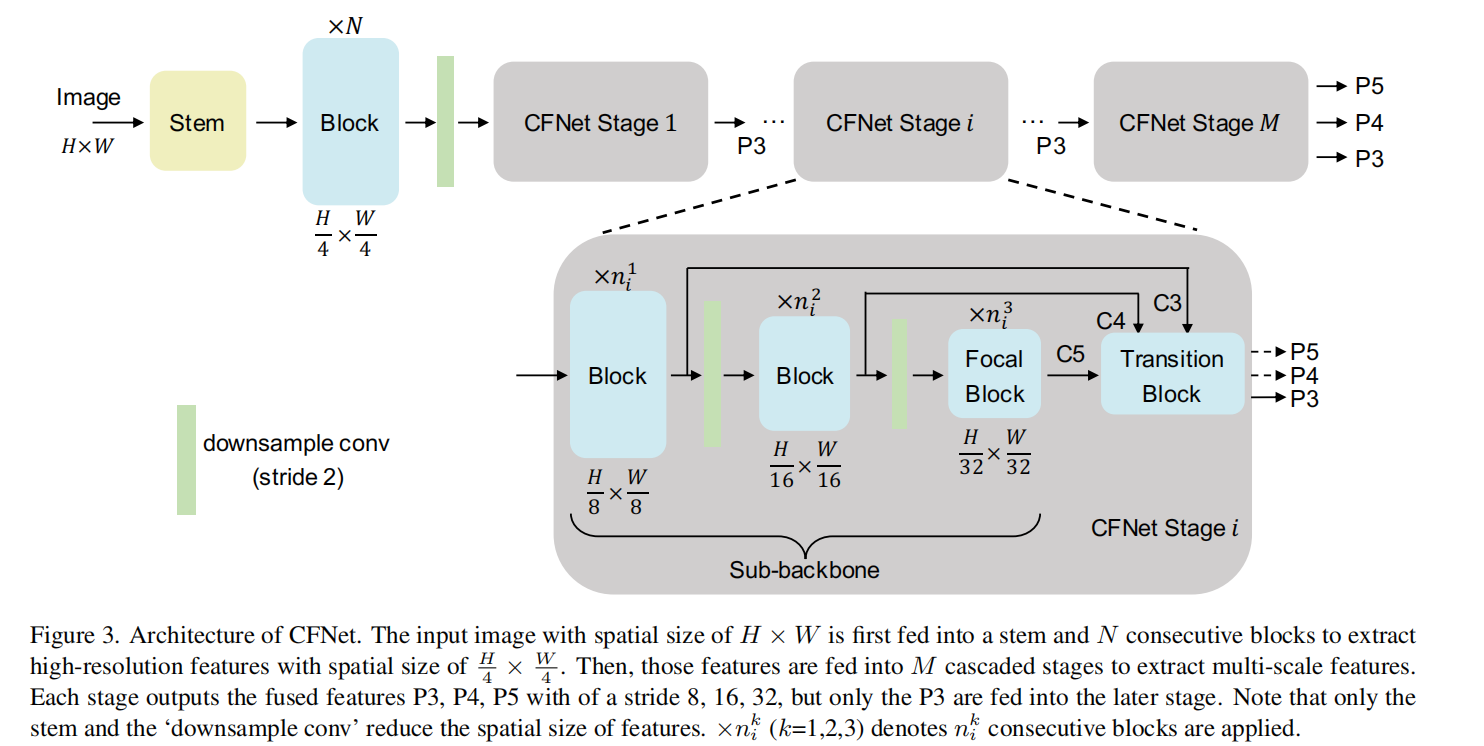 如图是我们的网络结构,可以看做是吧不同尺度的特征进行了重组的结果.每个块的结构一致,但是他们的大小不一样。具体来说,每个阶段都有一个用与提取特征的主干和用与集成特征的轻量过度块。我们将特征集成操作插入到主干中,以便在转换快之后可以在所有阶段进行转换,也就是过渡块之后的所有参数可以用于特征融合。
如图是我们的网络结构,可以看做是吧不同尺度的特征进行了重组的结果.每个块的结构一致,但是他们的大小不一样。具体来说,每个阶段都有一个用与提取特征的主干和用与集成特征的轻量过度块。我们将特征集成操作插入到主干中,以便在转换快之后可以在所有阶段进行转换,也就是过渡块之后的所有参数可以用于特征融合。
Overall Architecture
一张大小为HxW的输入的RGB图片输入到stem和N个连续块中,得到大小的高位特征,其中stem包含2个3x3的卷积,步长为2,连续快可以是仍和的神经网络,比如ResNet或者Swin Transformer等网络。
在输入到M级联stage之前,使用2x2卷积进行下采样。每个stage的结构一致,但是他们的大小不同,例如有不同数目的块。具体来说,每个stage包含一个子主干网络和一个轻微的连续块用与提取和聚合特征
过渡块
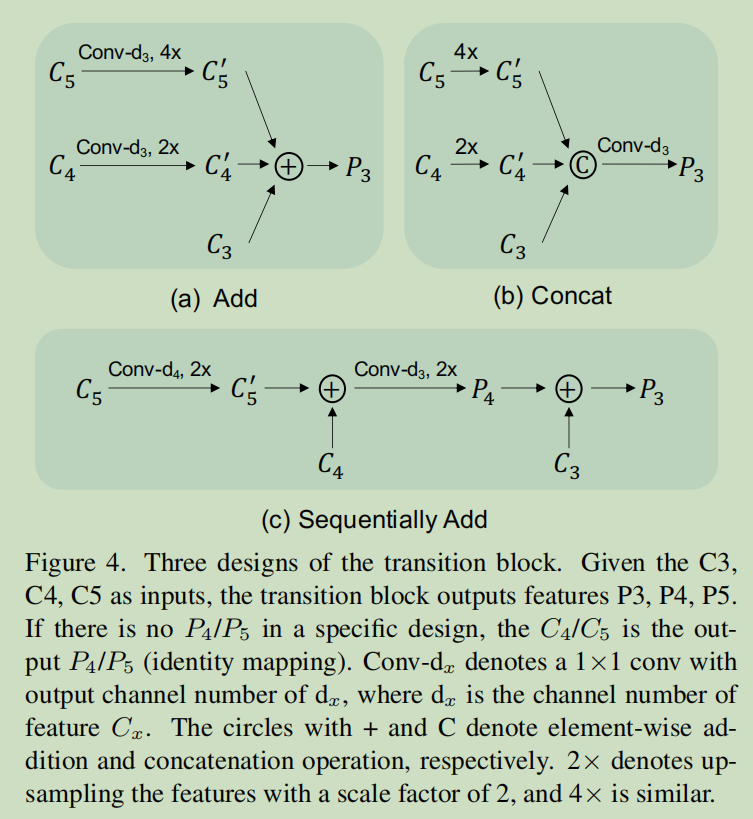
过渡块是为了聚合每个阶段的不同尺度的特征,为了避免引入太多的开销,我们提出了三种简单的设计,如下图所示,
- Add fusion首先把c4和c5的通道数减少到和c3一样,然后采用双线性差值来把大小扩充到一样
- Concat fusion把c5和c4上采样到和c3一致,然后concat,在使用一个1x1卷积减少通道数,
- sequence add fusion上采样并且把不同尺度的特征逐级结合在一起,这个设计类似FPN,除了这里没有额外的卷积操作
上述的三种模块里的Sequence Add的效果最好
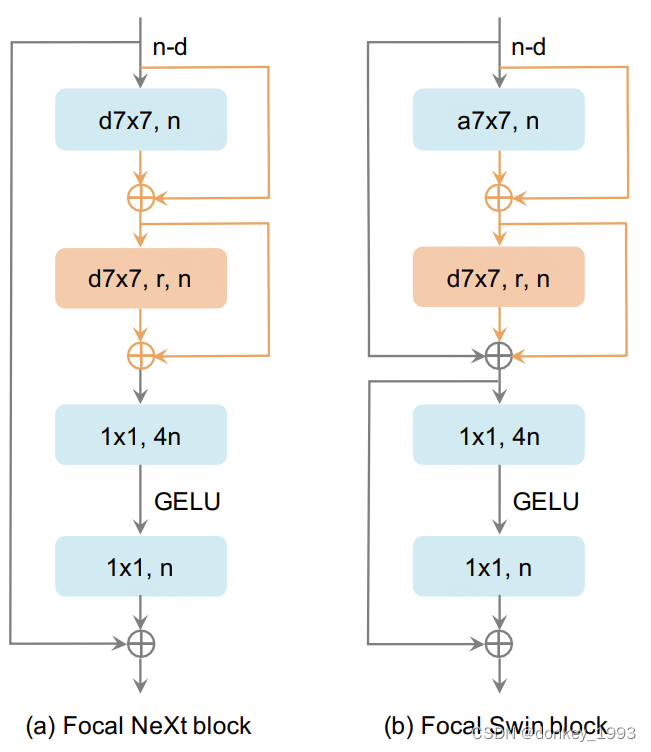
Focal block
对于密集预测任务,如何处理多尺度的物体是一个巨大的挑战,一个广泛使用的方案是生成不同分辨率的特征,比如生成步幅为8/16//128的特征来检测相应的物体。大步幅的特征有更大的感受野。在CFNet的每个stage,有三个block来提取特征步长为8/16/32的特征。理想情况下,我们可以提取另外两个分辨率的特征来整合更多的特征尺度,但是这会引入更多的参数,因为后续的group的通道数会变得很大,因此我们提出了focal block,扩大每个阶段最后一块的神经元感受野作为替代方法。下图是使用的两种焦点块,分别是ConvNext和Swin Transformer的两个基础块,主要增加了黄色部分的7x7卷积扩大感受野,同时减少参数量