
Embracing Unimodal Aleatoric Uncertainty for Robust Multimodal Fusion
作为一个多模态学习的基础任务,多模态融合旨在补充单模态的限制.其中一个特征融合的挑战是:大多数的单模态数据在他们的特征空间中都包含了潜在的噪声,可能会影响多模态的交互.在这篇文章中,我们说明了单模态的潜在噪声可以被量化甚至通过对比学习来进一步的增强单模态嵌入的稳定性.特定的来说,我们提出了一种新的通用鲁棒多模态融合策略,叫做Embracing Aleatoric Uncertainty(EAU).它包含了两个主要步骤:1. 稳定的单模态特征增强(SUFA) 2)鲁棒的多模态特征聚合(SUFA)
2963 字
|
15 分钟
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
多模态学习通常依赖于假设:训练和推理阶段所有的模态都是可用的.但在真实生活中完全获得全部的多模态数据非常困难,这通常会导致确实模态的问题这不仅对多模态预训练模型的可用性构成了巨大的障碍,还对其微调和下游任务的鲁棒性保持提出了挑战。为了应对这个问题,我们提出了一种新颖的架构,把单模态预训练模型的参数高效微调方法和自监督联合嵌入方法结合,这个架构能让模型预测缺失模态在特征空间中的表示.
1586 字
|
8 分钟
Predictive Dynamic Fusion
多模态融合在联合决策系统中对于做出总体决策是非常重要的,因为多模态数在开放的环境中发生改变,动态的融合在多个应用中取得了巨大进展.但是,大多数的动态多模态融合系统缺少理论的保证并且容易陷入局部最优解从而产生不可靠和不稳定.为了解决这个问题,我们提出了预测动态融合(PDF)架构.我们从泛化的角度揭示了多模态融合,并从理论上推导了具有单置信和全置信的可预测协同信念(共同信念),证明降低了泛化误差的上界。
1753 字
|
9 分钟
空洞卷积
空洞卷积(Dilated convolutions)的也叫膨胀卷积或者扩张卷积,是为了解决图像分割问题提出,传统的分割需要使用池化+卷积来增加感受野,然后上采样还原图像尺寸,特征图的缩小再放大造成了一定程度上的精度损失.因此需要一种操作可以增加感受野的同时保持特征图的尺寸不变,代替上下采样,因此空洞卷积诞生了.当然我们也可以使用U-Net这种网络来进行特征补充.
419 字
|
2 分钟
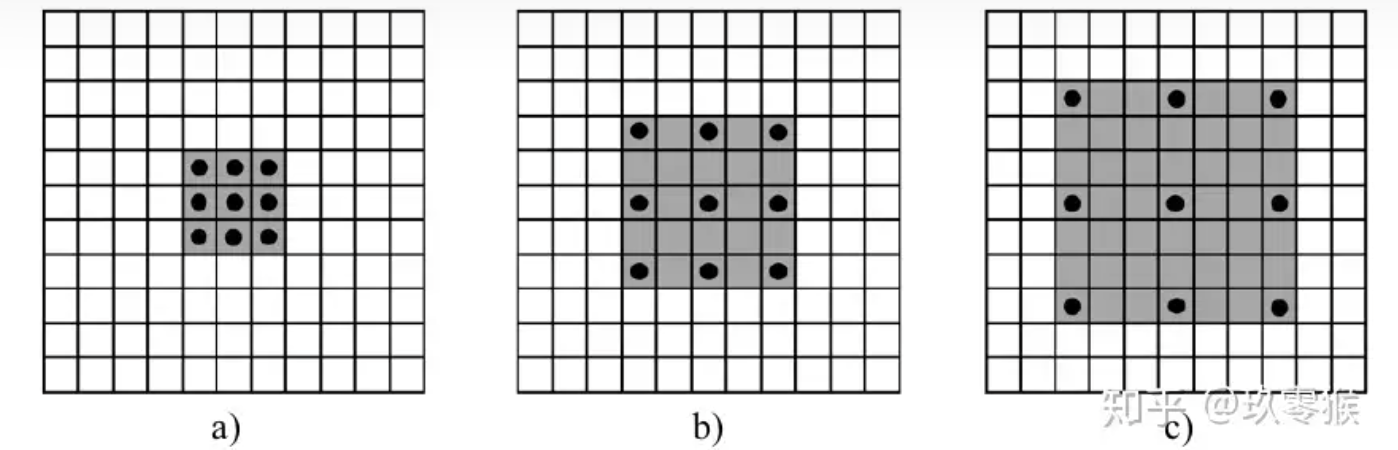
DilateFormer:Multi-Scale Dilated Transformer for Visual Recognition
原始ViT被鼓励在异质两个图像patch中建立长距离联系,而两一个ViT受到CNN的启发,只在小块的patch中建立联系.前者会导致复杂度二次方增长,而后者受到小感受野的限制.在本文中,我们探索了怎么在复杂度和感受野之间进行一个trade-off的取舍.通过分析全局注意力在不同patch之间的交互,我们在浅层观察到两个关键特性,局部性和稀疏性,表明在vit的浅层的全局注意力中存在一定的冗余.因此,我们提出了Mutil-Scale Dilated Attention来在滑动窗口内建模局部和稀疏的patch相互作用,通过金字塔结构,我们通过把MSDA blocks在底层堆积和全局的多头注意力机制在高层堆积形成了我们的网络.
1013 字
|
5 分钟
交叉熵
在信息论中,基于相同事件测度的两个概率分布p和q的交叉熵(英语:Cross entropy)是指,当基于一个“非自然”(相对于“真实”分布p)的概率分布q进行编码时,在事件集合中唯一标识一个事件所需要的平均比特数(bit)。
139 字
|
1 分钟